1.SimMatch:基于相似度匹配的半监督学习
摘要
在计算机视觉和机器学习研究领域,使用少量标记数据进行学习一直是一个长期存在的问题。本文提出了一种新的半监督学习框架SimMatch,该框架同时考虑了语义相似度和实例相似度。在SimMatch中,一致性正则化将同时应用于语义级和实例级。鼓励同一实例的不同增强视图具有与其他实例相同的类预测和相似关系。接下来,我们实例化一个标记的内存缓冲区,以充分利用实例级的基本事实标签,并弥合语义和实例相似性之间的差距。最后,我们提出了一种可使这两个相似点相互同构变换的展开和聚合运算。通过这种方式,语义伪标签和实例伪标签可以相互传播,从而生成更高质量和更可靠的匹配目标。大量的实验结果表明,SimMatch提高了跨不同基准数据集和不同设置的半监督学习任务的性能。值得注意的是,在400轮次的训练中,SimMatch在ImageNet上1%和10%的标记示例中获得了67.2%和74.4%的Top-1准确性,显著优于基线方法,优于以前的半监督学习框架。代码和预先训练的模型可在https://github.com/KyleZheng1997/simmatch获得。
1.导语
得益于过去几十年大规模标注数据集的可用性和不断增长的计算资源,深度神经网络已经证明了它们在各种视觉任务上的成功[19,21,22,26,36,48,56]。然而,在现实场景中收集大量的标记数据是非常昂贵的。在计算机视觉和机器学习研究领域,使用少量标记数据进行学习一直是一个长期存在的问题。在各种方法中,半监督学习(SSL)[12,44,51,63]借助海量的无标记数据,是一种有效的解决方案,并取得了显著的性能。
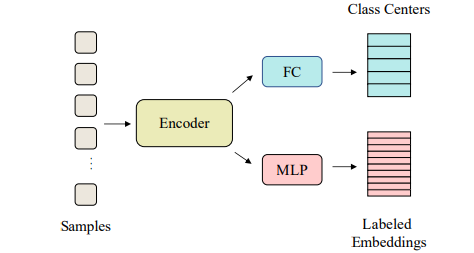
图1所示。SimMatch的草图。全连通层向量可以被视为每个类别的语义代表或类中心。然而,由于标记样本有限,语义级信息并不总是可靠的。在SimMatch中,我们同时考虑了实例级和语义级的信息,并采用带标签的内存缓冲区来充分利用实例级的ground truth标签。
一种简单但非常有效的半监督学习方法是在大规模数据集上对模型进行预训练,然后通过使用少量标记样本对预训练的模型进行微调来转移学习到的表示。由于自监督学习的最新进展[10,14,15,20,24,25,52],这种预训练和微调管道在SSL中表现出了良好的性能。大多数自我监督学习框架关注借口任务的设计。例如,实例区分[53]鼓励同一实例的不同视图共享相同的特性,而不同实例应该具有不同的特性。基于深度聚类的方法[3,9,10]期望将同一实例的不同增强视图分类到同一聚类中。然而,这些借口任务大多是在完全没有监督的情况下设计的,没有考虑到手头为数不多的标记数据。
目前流行的方法不是独立的两阶段预训练和精细调优,而是直接将标记数据与伪标记[33]或一致性正则化[45]联合在一个特征学习范式中进行。这些方法背后的主要思想是训练带有标记样本的语义分类器,并使用预测的分布作为未标记样本的伪标签。这样,伪标签一般由弱增广视图[5,46]或多个强增广视图[6]的平均预测产生。目标将由不同的强增强视图和伪标签之间的交叉熵损失来构建。还需要注意的是,伪标签通常会被锐化或由argmar操作,因为每个实例都被归入一个类别。然而,当标注数据非常有限时,语义分类器就不再可靠;应用伪标签方法会导致“过度自信”问题[13,59],这意味着模型将适合自信但错误的伪标签,导致性能较差。
在本文中,我们介绍了一种新的半监督学习框架SimMatch,如图1所示。在SimMatch中,我们将两者连接起来,并提出在不同的扩展中同时匹配语义级和实例级的相似关系。具体来说,我们首先要求强增强视图与弱增强视图具有相同的语义相似性(即标签预测);此外,我们还鼓励强增强与弱增强具有相同的实例特征(即实例之间的相似度),以获得更多的内在特征匹配。此外,不同于以往的工作将弱增强视图的预测简单地视为伪标签。在SimMatch中,语义伪标签和实例伪标签可以通过实例化一个保存所有标记示例的内存缓冲区进行交互。这样,通过引入聚合和展开技术,可以实现这两个相似点之间的同构转换。这样语义伪标签和实例伪标签就可以相互传播,从而生成更高质量、更可靠的匹配目标。大量的实验证明了SimMatch在不同设置下的有效性。我们的贡献可以概括如下:
· 我们提出了一种新的半监督学习框架SimMatch,它同时考虑语义相似度和实例相似度。
· 为了传递这两种相似之处,我们利用一个标记的内存缓冲区,以便语义和实例伪标签可以通过聚合和展开技术相互传播。
·SimMatch为半监督学习建立了一种新的最先进的性能。SimMatch只训练了400个阶段,在ImageNet上有1%和10%的标记示例,获得了67.2%和74.4%的Top-1准确性。
2. 相关工作
2.1 半监督学习
一致性正则化是半监督学习中广泛采用的一种方法。其主要思想是强制模型为同一实例的不同受扰动版本输出一致的预测。例如,[32,45]通过最小化两个变换视图的预测概率分布的均方差来达到这种一致性要求。在这种情况下,转换既可以是特定领域的数据增强[5,6,46],也可以是网络中的一些正则化技术(例如,删除[47]和随机最大池[45])。此外,[32]还提出了一种时间集合策略,将多个先前网络的预测集合起来,使得预测分布更加可靠。Mean Teacher[50]进一步扩展了这一想法,用指数移动平均(EMA)模型的输出取代了聚合预测。
MixMatch[6]、ReMixMatch[5]和FixMatch[46]是三种基于增强锚定的方法,它们充分利用了增强一致性。具体来说,MixMatch采用多个强增强视图的锐化平均预测作为伪标签,并利用MixUp技巧[60]进一步增强伪标签。ReMixMatch通过生成带有弱增强视图的伪标签改进了这一思想,还引入了一种分布对齐策略,该策略鼓励伪标签分布与地面真实类标签的边缘分布相匹配。FixMatch简化了这些想法,只有在模型产生高置信度伪标签时,才保留未标记的图像。尽管FixMatch很简单,但它在基于增强锚定的方法中取得了最先进的性能。
2.2 自监督预训练
除了典型的半监督学习方法外,自监督和对比学习[14,25,53]也在这一研究领域获得了很大的关注,因为使用标记样本对预训练模型进行微调显示了有前景的分类结果,特别是SimCLR v2[15]表明,大(深度和广度)预训练模型是强半监督学习者。大多数对比学习框架采用实例辨别[53]作为借口任务,将同一实例的不同增强视图定义为正对,而将不同实例的视图采样形成负对。但是,由于相似样本的存在,将不同实例作为负对处理会导致类冲突问题[2],不利于下游任务(特别是分类任务)。以前的一些工作通过无监督聚类解决了这个问题[9,10,35,61],将相似的样本聚到同一个类中。还有一些方法设计了各种消极自由借口任务[17,24,28,29,62]来避免类冲突问题。基于聚类的方法和基于无负极性的方法对于下游分类任务都有显著的改进。
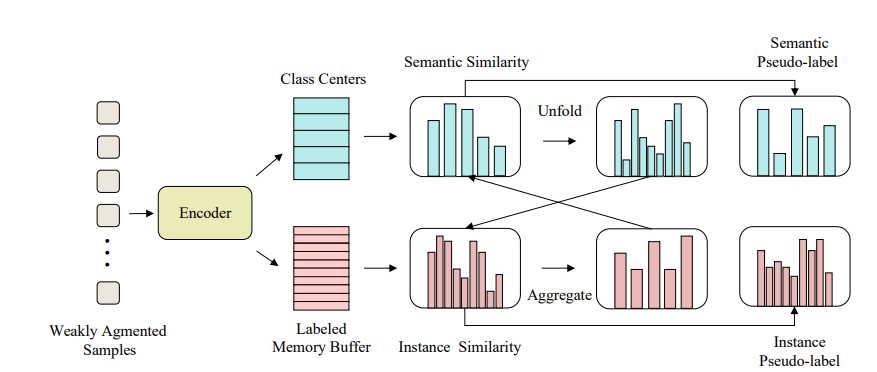
图2。SimMatch伪标签生成过程的概述。SimMatch将使用弱增强视图生成语义伪标签和实例伪标签。具体来说,我们将首先通过类中心和标签嵌入计算语义和实例相似度,然后使用展开和聚合操作将这两个相似度融合,最后得到伪标签。请在下面的方法部分查看更多详细信息。
CoMatch[34]结合了一致性正则化和对比学习的思想,通过两个类概率分布之间的相似性来衡量两个实例的目标相似性,在半监督学习中取得了目前最先进的性能。然而,它对超参数非常敏感,对于不同的数据集和设置,最佳温度和阈值是不同的。与commatch相比,SimMatch速度更快、健壮性更强、性能更高。
3. 方法
我们将半监督图像分类问题定义如下。给定一批B标记的样本,我们随机应用弱增强函数(例如,只使用翻转和裁剪)Tw(-)来获得弱增强样本。然后,使用基于卷积神经网络的编码器F(·)从这些样本中提取特征信息,即h= F(T(x))。最后,利用一个全连接的类预测头φ(·)将hb映射为语义相似度,可以写成:p = φ(h)。标记样本可以通过与真实标签的交叉熵损失直接优化:
(1)
让我们定义一批 未标记的样本 。按照[5,6],我们随机应用弱增广和强增广Tw (-), Ts(-),采用与标记样本相同的处理步骤,得到弱增广样本pW(伪标签)和强增广样本p*的语义相似性。那么无监督分类损失可以定义为这两个预测之间的交叉误差:
(2)
其中r为置信阈值。在[46]之后,我们只保留伪标签中最大类概率大于t的未标记样本。DA(·)表示来自[5]的平衡伪标签分布的分布对齐策略。我们只需要遵循[34w]的实现,在这里我们保持 的移动平均值,并使用调整当前的p。另外请注意,我们不采用锐化版或one-hot(独热)的, 将直接作为伪标签。
3.2 实例相似性匹配
在SimMatch中,我们还考虑了先前讨论过的实例级相似度。鼓励强增强视图与弱增强视图具有相似的相似度分布。假设我们有一个非线性投影头g(·),它将表示h映射到低维嵌入。遵循基于锚定的方法,我们使用和来表示来自弱增强视图和强增强视图的嵌入。现在,让我们假设我们对一堆不同的样本有K个弱增广嵌入$\lbrace z_k: k ∈(1,…, K)\rbrace $,我们通过使用相似度函数 来计算 和第i个实例之间的相似度,它表示归一化向量。softmax层可以处理计算出的相似度,然后产生一个分布:
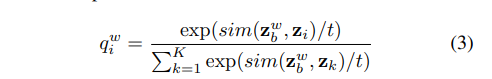
其中为控制分布锐度的温度参数。另一方面,我们可以计算强增广视图和之间的相似度,如。得到的相似度分布可以写成:
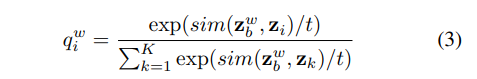
最后,通过最小化和之间的差异来实现一致性正则化。这里我们采用交叉熵损失,它可以表述为:
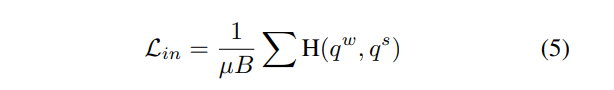
请注意,实例一致性正则化只应用于未标记的示例。我们模型的总体训练目标是:
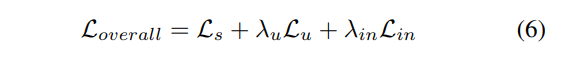
其中和是控制两种损失权重的平衡因素。
3.3 通过SimMatch进行标签传播
虽然我们的总体训练目标也考虑了实例级的一致性正则化,但是实例伪标签的生成仍然是完全无监督的,这绝对是对标记信息的浪费。为了提高伪标签的质量,在本节中,我们将演示如何在实例级别上利用标记信息,并介绍一种允许语义相似性和实例相似性相互交互的方法。
我们实例化了一个带标签的内存缓冲区来保存所有带注释的示例,如图2所示(红色分支)。这样,我们在Eq.(3)和Eq.(4)中使用的每个都可以分配给一个特定的类。如果我们将中的向量解释为“居中”类引用,那么标记内存缓冲区中的嵌入可以被视为一组“单独的”类引用。
通过给定一个弱增广样本,首先计算语义相似度 和实例相似度 。(注意L通常比K小得多,因为每个类至少需要一个样本。)为了用标_w定,我们需要将展开到K维空间中,我们将其表示为 。我们通过为每个标记的嵌入匹配相应的语义相似度来实现这一点:
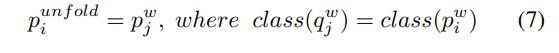
其中class(·)是返回基础真值类的函数。具体来说,表示内存缓冲区中第j个元素的标签,表示第i个类。现在,我们通过 缩放 来重新生成校正后的实例伪标签,可以表示为:
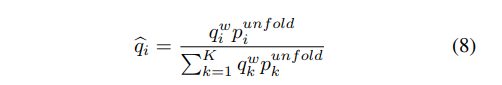
将校正后的实例伪标签 作为新目标,取代式(5)中的旧目标 。另一方面,我们也可以利用实例相似度来调整语义相似度。要做到这一点,我们首先需要将q聚合到L维空间中,我们将其标记为 。我们通过对具有相同基础真理标签的实例相似性求和来实现这一点:
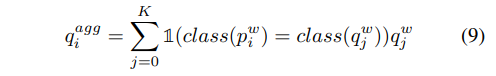
现在,我们用 平滑 ,重新生成调整后的语义伪标签,可以写成:
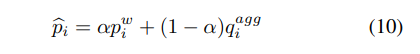
其中α是控制语义和实例信息权重的超参数。同理,调整后的语义伪标签将取代公式(2)中原来的p。通过这种方式,伪标签p和q都将包含语义级和实例级信息。正如我们在图3中所示,当语义和实例相似性相似时,这意味着这两个分布彼此的预测一致,那么结果伪标签将更加清晰,并为某些类产生高置信度。另一方面,如果这两个相似点不同,结果伪标签将更平坦,不包含高概率值。在SimMatch中,我们分别对q和p采用了缩放和平滑策略,我们也尝试了这两种策略的不同组合,详情请参见我们的烧蚀研究部分。
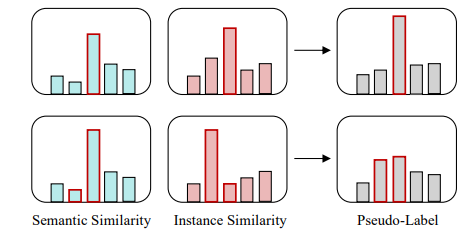
图3。标签传播背后的直觉。如果语义和实例相似,结果伪标签将更加清晰,并为某些类产生高置信度。当这两个相似点不同时,结果伪标签会更平坦。
3.4 高效内存缓冲区
如前所述,SimMatch需要一个内存缓冲区来保存标记示例的嵌入。在这样做的过程中,我们需要同时存储特征嵌入和基础真实标签。具体来说,我们定义了一个特征内存缓冲区 $Q_{f} ∈ R^{K×D} $ 和一个标签内存缓冲区 $Q_l ∈ R^{K × l} $ ,其中K为可用的标注样本数量,D为嵌入大小。在我们的实验中最大的K大约是 (ImageNet 10%设置),这只需要64M GPU内存用于 。对于 ,我们只需要为每个标签存储一个标量,聚合和展开操作可以通过 和 函数轻松实现,这应该已经在最近的深度学习库中得到了有效的实现[1,42]。在这种情况下, 的成本只比IM GPU内存(K = )低,这几乎可以忽略不计。
根据[25]的说法,内存缓冲区的快速变化特性将大大降低性能。在SimMatch中,我们针对不同的缓冲区大小采用了两种不同的实现。当K较大时,我们遵循MoCo[25]来利用一个基于师生的框架,我们将其表示为 和 。在这种情况下,标记示例和强增强样本将被传递到 中,弱增强样本将被输入到 中生成伪标签。 的参数将按以下方式更新:
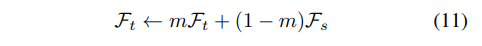
另一方面,当K较小时,不需要维护教师网络,我们简单地采用时间集成策略[32,53]来平滑内存缓冲区中的特征,可写为:
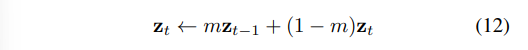
在这种情况下,所有的样本将直接传递到相同的编码器。SimMatch的师生版已在算法1中说明。

4. 实验
在本节中,我们将首先在各种数据集和设置上测试SimMatch,以显示其优越性,然后我们将消融每个组件,以验证框架中每个组件的有效性。
4.1 CIFAR-10 和 CIFAR-100
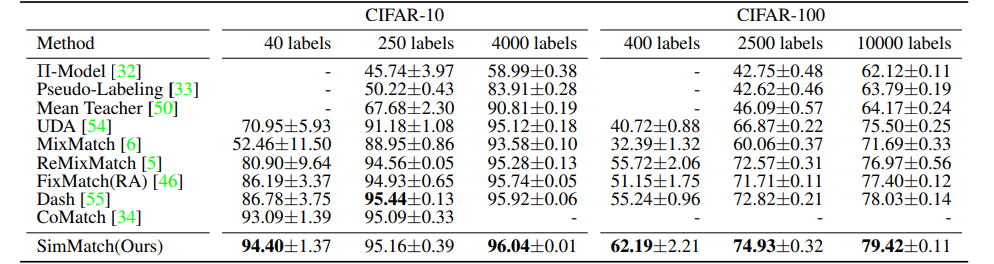
表1.在CIFAR-10和CIFAR-100上使用不同的标签设置尺寸进行精度比较(平均值和标准超过5次)。
我们首先在CIFAR-10和CIFAR100[31]数据集上评估SimMatch。CIFAR-10包含60000张32x32彩色图像,分为10个类,每类6000张图像。有50000张训练图片和10000张测试图片。CIFAR-100与CIFAR-10类似,只是它有100个类,每个类包含600张图像。每个类别有500张训练图片和100张测试图片。对于CIFAR-10,我们从训练集中随机抽取4、25和400个样本作为标记数据,并使用训练集的其余部分作为未标记数据。对于CIFAR-100,我们执行相同的实验,但每个类使用4、25和100个样本。
实现细节。我们的大多数实现都遵循[46]。具体来说,我们分别为CIFAR-10和CIFAR-100采用WRN28-2和WRN28-8[57]。我们使用带有Nesterov 动量的标准SGD优化器,并设置初始学习率为0.03。对于学习率计划,我们使用余弦学习率衰减[38],它将学习率调整为 ,其中s是当前的训练步骤,S是训练步骤的总数。我们还使用模型参数的指数移动平均报告最终性能。注意,我们对两个数据集使用了相同的超参数集 $ α = 0.9$ , , , , , ) 。对于分布对齐,我们累积过去32步 来计算移动平均 。我们采用时间集合内存缓冲区[32],因为这两个数据集的大多数设置都有一个相对较小的k。对于强增强和弱增强的实现,我们严格遵循FixMatch[46]。
结果。结果已在表1中表明。对于基线,我们主要考虑方法I-Model [32],伪标签[33],Mean Teacher [50], UDA [54], Mix匹配[6]、ReMixMatch[5]、FixMatch[46]和CoMatch[34]。我们计算精度的平均值和方差,当训练5个不同的“折叠”标签数据。正如我们所看到的,SimMatch在各种设置上实现了最先进的性能,特别是在CIFAR-100上。对于CIFAR-10, SimMatch在40个标签设置上有很大的性能提高,但在250和4000标签设置上的改进相对较小。我们怀疑这是因为95% ~ 96%的准确性已经非常接近监督性能
4.2 ImageNet-1k
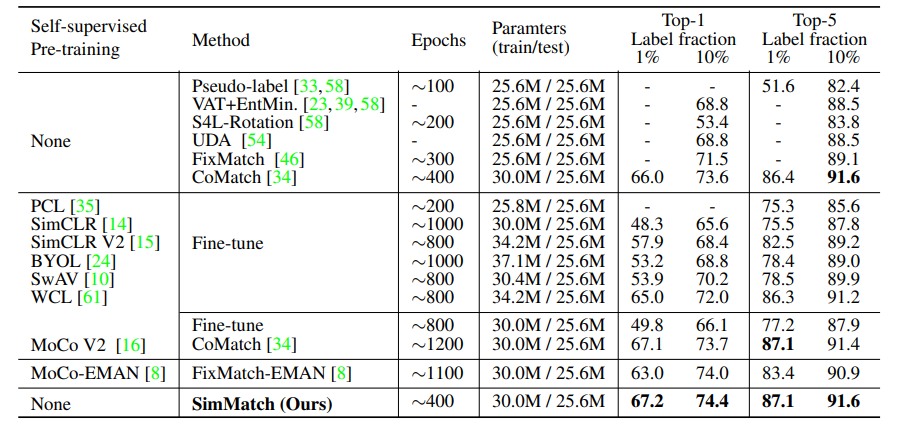
表2.ImageNet上1%和10%标记示例的实验结果。
我们还在大规模ImageNet-1k数据集[19]上进行了SimMatch,以显示其优越性。具体来说,我们在1%和10%的设置下测试我们的算法。我们遵循与CoMatch[34]中相同的标签生成过程,其中每个类将分别为1%和10%的设置选择13和128个标记样本。
实现细节。对于ImageNet-1k,我们采用ResNet-50[27],并使用具有Nesterov动量的标准SGD优化器。我们对模型进行5个周期的预热,直到它达到初始学习率0.03,然后余弦衰减到0。我们对1%和10%的设置使用相同的超参数集( = 10, =5, = 0.1, = 0.9, = 0.7, =5, = 0.999, = 64)。我们保留过去的256步 用于分布对齐。我们选择了学生-教师版本的内存缓冲区,并在学生网络上测试了性能。对于强增强,我们在MoCo v2[16]中遵循相同的策略。
结果。我们在表2中显示了结果。可以看到,在400课时的训练下,SimMatch在1%和10%的标记样例上的Top-1准确率分别为67.2%和74.4%,显著优于之前的方法。FixMatch-EMAN[8]在10%设置下的性能略低(74.0%)。然而,它需要800代的自监督预训练(MoCoEMAN), SimMatch可以直接从头开始训练。最新的工作PAWS[4]在300课时的训练下,在1%和10%的设置下达到66.5%和75.5%的Top-1准确率。然而,PAWS需要多作物策略[10]和970 x 7标记的例子来构建支持集。在每个时代,PAWS的实际训练FLOPS是SimMatch的4倍。因此,报告的300 epoch PAWS应该具有与1200 epoch SimMatch相似的训练FLOPS。由于GPU资源有限,我们无法将这项研究推进到这样的规模,但由于SimMatch在1%设置下,用1/3训练成本(400 epoch)超过了PAWS,我们相信它已经可以证明我们方法的优越性
表3.使用ImageNet预训练的ResNet-50转移学习性能。根据[14,24]的评估协议,我们报告了除宠物和鲜花以外的Top-1分类精度,我们报告的是每类平均精度。

迁移学习。我们还评估了学习到的多个下游分类任务的表示。我们遵循[14,24]中描述的线性评估设置。具体来说,我们训练了一个l2正则化多项式逻辑回归分类器,从冻结的预训练网络(400期10% SimMatch)提取特征,然后我们使用L-BFGS[37]优化softmax交叉熵目标,我们没有应用数据增强。我们从验证分段中选取最佳l2正则化参数和学习率,并将其应用于测试集。在这个基准测试中使用的数据集如下:CIFAR-10 [31], CIFAR-100 [31], 食品101 [7], 汽车 [30],DTD[18],宠物[41],鲜花[40]。结果如表3所示。我们可以看到,SimMatch仅用400个epoch的训练,就在CIFAR-10, CIFAR-100, Cars和Flowers数据集上取得了与BYOL相当的最佳性能,并明显优于SimCLR, MoCo V2和有监督的基线。这些结果进一步验证了SimMatch在分类任务上的表示质量。
表4.不同方法的GPU小时每epoch。在8个NVIDIA V100 gpu上测试速度。
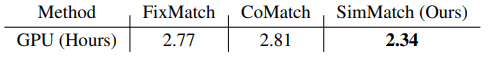
训练效率。接下来,我们测试FixMatch、CoMatch和SimMatch的实际训练速度。结果如表4所示,SimMatch比FixMatch和CoMatch快近17%。在FixMatch中,弱增强的11将被传递到在线网络中,这将为额外的计算图消耗更多的资源。但是在SimMatch中,U只需要传入EMA网络,所以不需要保留计算图。与CoMatch对EMA网络需要两次向前通过(强增强和弱增强1U)相比,SimMatch只需要一次通过。此外,CoMatch采用4个内存库(258M memory)计算伪标签;对于1%和10%的标签,SimMatch只需要两个6.4M / 64M内存的内存库,因此伪标签的生成也会更快。
4.3 消融实验
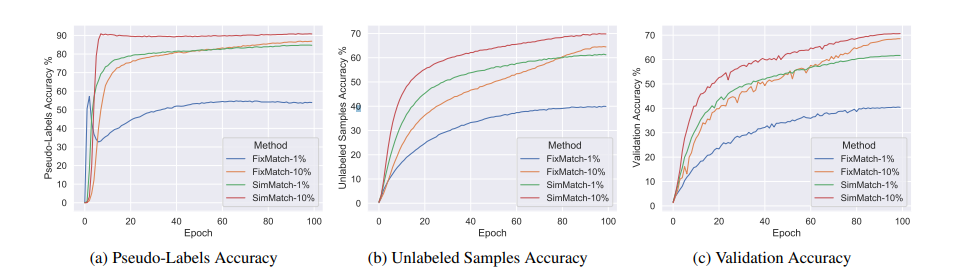
图4.(a)伪标签的准确性- p的置信度高于阈值的准确性,(b)未标记样本的准确性-所有不考虑阈值的准确性,(c) FixMatch和SimMatch在1%和10%设置下的验证准确性。
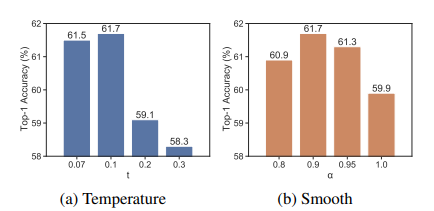
图5.改变t和a的结果(ImageNct-1k 1% - 100 cp)
表5所示。去除尺度和平滑策略的结果。(图片网-1k 1% - 100 EP)
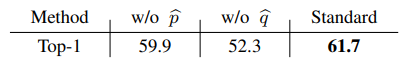
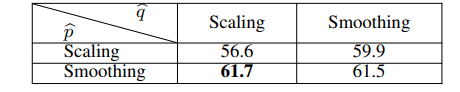
表6所示。不同组合的缩放和平滑策略的结果。(ImageNet-1k 1% - 100ep)
Pseudo-Label准确性。首先,我们想展示SimMatch的伪标签准确性。在图4中,我们可视化了FixMatch和我们的方法的训练进度。SimMatch总是可以生成高质量的伪标签,并且在未标记的样本和验证集上始终具有更高的性能。
温度。Eq.(4)和Eq.(3)中的温度 控制了实例分布的锐度。(注意 等价于 运算)。我们在图5a中展示了不同t值的变化结果。可以看出,当 $ t = 0.1$ 时,Top-1精度最好,当 时,Top-1精度略有下降。这与最近的对比学习研究一致, 通常是最佳温度[10,11,14,15]。
平滑的参数。我们还在图5b中展示了不同光滑参数a Eq.(10)的有效性。具体来说,我们对a扫过[0.8,0.9,0.95,1.0],可以清楚地看到a = 0.9达到了最好的结果。注意,a = 1.0相当于直接取等式(2)的原始伪标签pW,这会导致1.8%的性能下降。
标签传播。接下来,我们要验证标签传播的有效性。结果如表5所示。当我们删除p时,a = 1.0也是一样的情况,所以我们不再进一步讨论这个设置。如果我们删除 ,这意味着投影头将以完全无监督的方式进行训练,如[62]所示,我们可以看到性能明显低于标准SimMatch,这表明了我们的标签传播策略的重要性。
传播策略。然后,我们尝试了缩放和平滑策略的不同组合来生成。从表6可以看出,对p取平滑,对q取缩放,得到的结果最好。我们可能会注意到,对p和q应用平滑可以获得相似的性能(61.5%)。然而,平滑策略将引入一个平滑参数。因此,为了保持我们的框架简单,我们更倾向于选择q的缩放策略。
实例匹配损耗设计。为了验证实例相似度匹配项 的有效性,我们将 替换为 InfoNCE 和 SwAV 。当使用InfoNCE损耗时,我们将温度扫过[0.07,0.1,0.2]。在这种情况下,我们能得到的最佳结果是53.5%,比SimMatch低8.2%。这是由于分类问题和InfoNCE目标之间的自然冲突。具体来说,分类问题的目的是将相似的样本分组在一起,而InfoNCE的目的是区分每个实例。在使用SwAV时,我们尝试将原型数量设置为1000、3000和10000。最终得到的最好结果为49.7%,比SimMatch降低了12%。SwAV的目标是将样本平均分配给每个原型,防止模型崩溃。然而,分布对齐也有类似的目标,SimMatch在Eq(2)中采用了这一目标。此外,SwAV损失将以完全无监督的方式进行训练,这将失去标签的力量。 的优点是标签信息可以很容易地与实例相似度相配合。
5. 结论
在本文中,我们提出了一种新的半监督学习框架SimMatch,该框架同时考虑了语义级和实例级的一致性正则化。我们还引入了一个标记内存缓冲区,以充分利用实例级的数据注释。最后,我们定义的展开和聚合操作允许标签在语义级和实例级信息之间传播。大量的实验证明了我们的框架中每个组件的有效性。在ImageNet-1K上的结果展示了半监督学习的最先进性能。




