模型推理服务
一、推理服务概述
深度学习模型的全生命周期
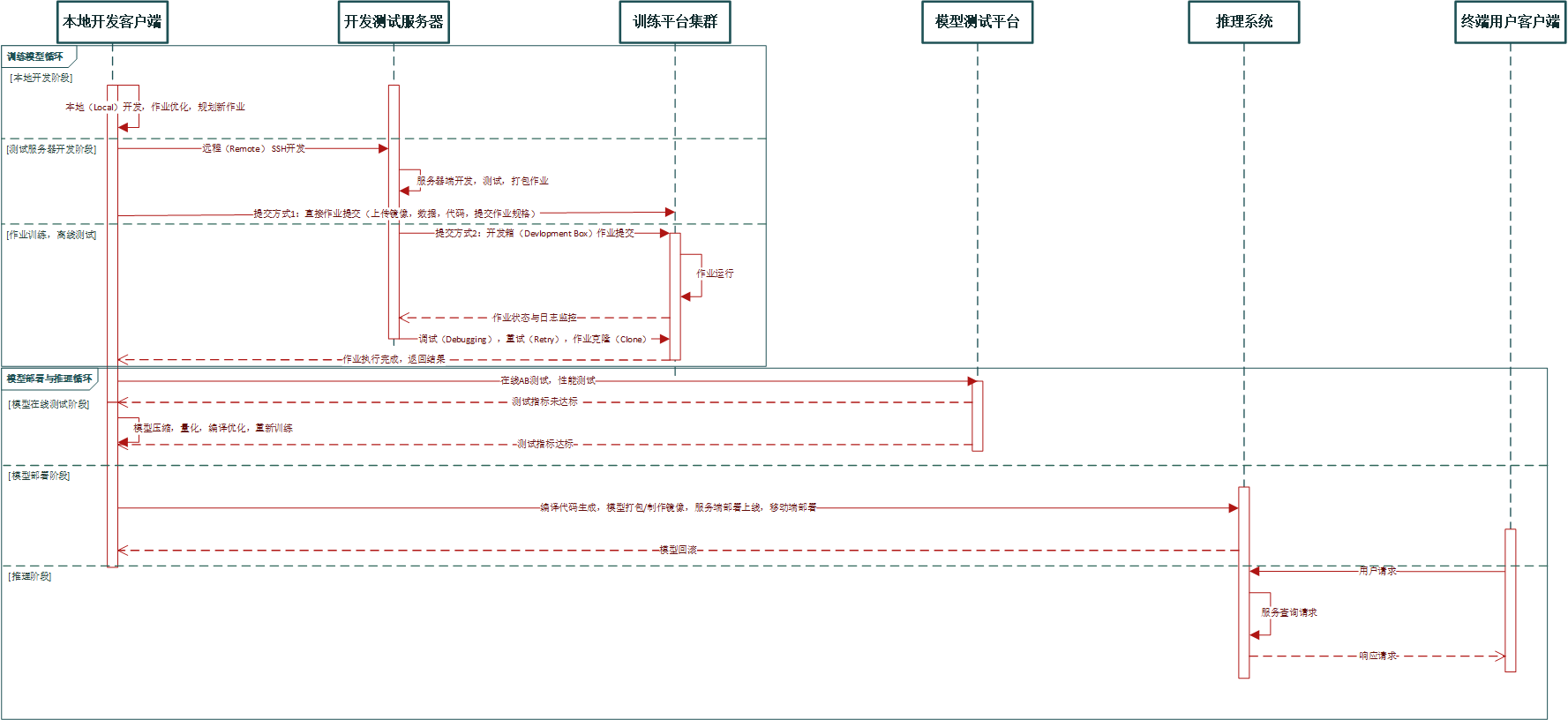
深度学习模型的全生命周期图,主要分为两大类任务,训练任务和推理任务。
推理、部署和服务化
-
训练任务:通常需要执行数小时、数天,一般配置较大的 batch size 以实现较大的吞吐量,训练模型直到指定的准确度或错误率。
-
推理任务:执行 7 x 24 小时服务,此时模型已稳定无需训练,服务于真实数据进行推理预测,一般 batch size 较小。
推理任务相比训练任务的挑战有如下几点:
-
模型被部署为长期运行的服务(需要稳定可靠);
-
推理时有更苛刻的资源约束(需要在有限算力下服务);
-
推理不需要反向传播梯度下降;
-
部署的设备型号更加多样,意味着设备架构多样(需要具有通用性)。
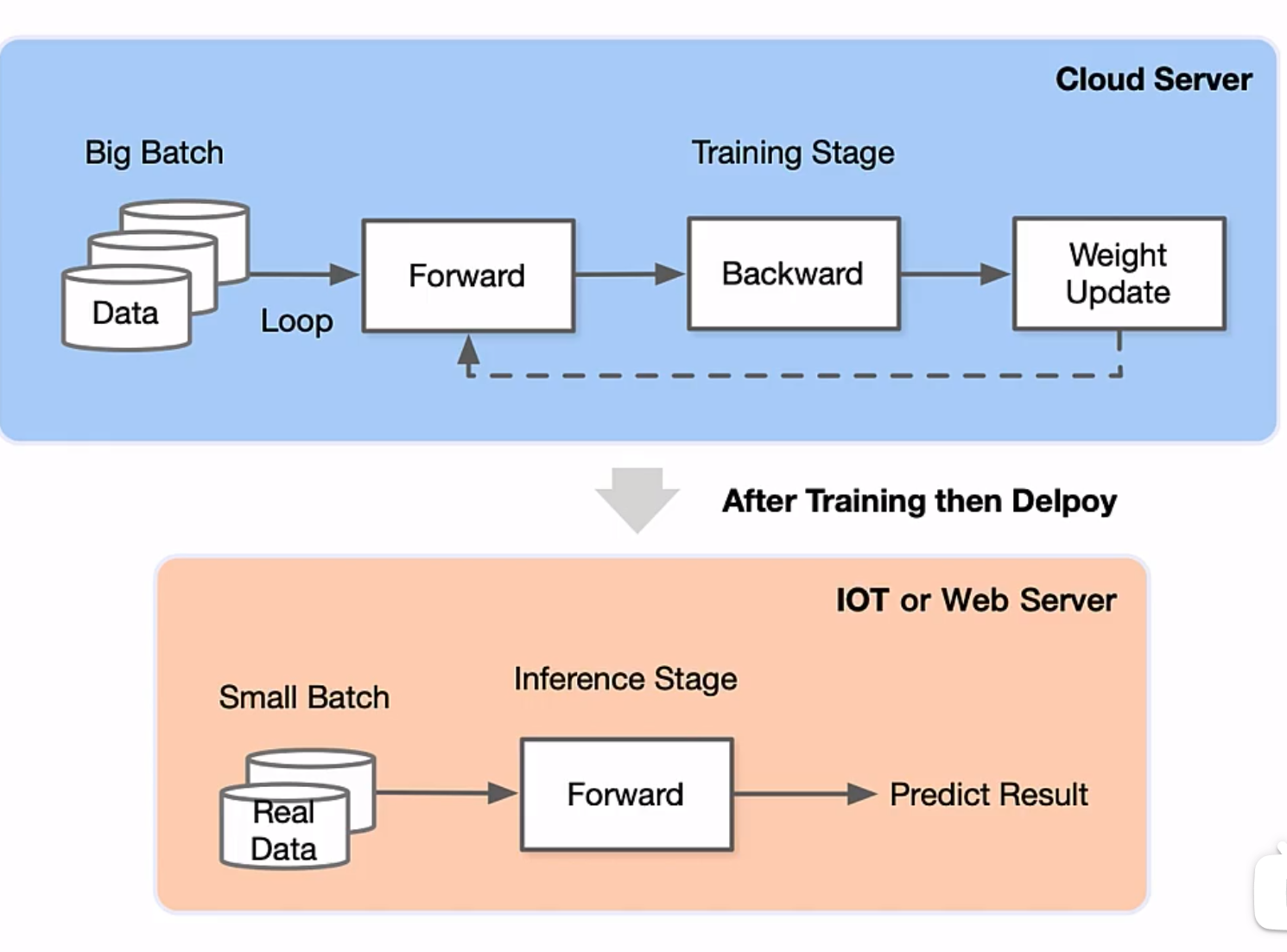
训练过程 通过设计合适的 AI 模型以及损失函数、优化算法等,前向传播并计算损失函数,反向计算梯度,利用优化函数来更新模型,最终目标是使损失函数最小。
推理过程 在训练好的模型上,进行一次前向传播得到输出,最终目标是将模型部署在生产环境中。
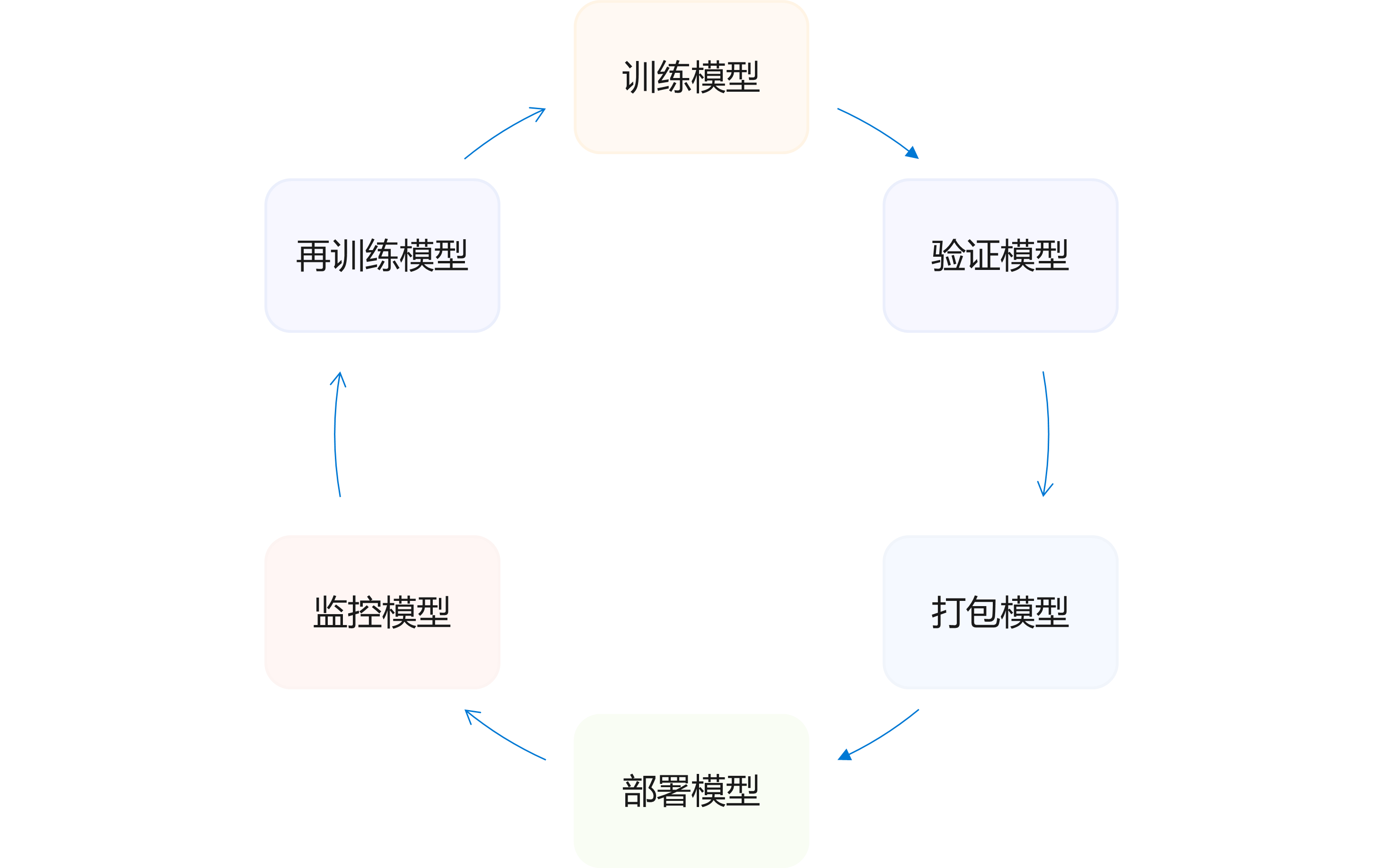
测试过程 一般此阶段含有功能性测试(离线测试和在线 A/B 测试等)和非功能性测试(性能测试等),一旦模型达标则可以进行模型部署阶段。
部署过程 需要针对的平台编译与代码生成,模型打包或者针对服务端制作镜像。一旦服务中出现问题,模型还可以通过一定策略进行回滚使用原来的模型。
服务过程 封装成一个SDK,集成到APP或者服务中;封装成一个web服务,对外暴露接口(HTTP(S),RPC等协议)。
二、推理系统与推理服务
推理系统
**推理系统(Inference System)**是用于部署人工智能模型,执行推理预测任务的人工智能系统,类似传统 Web 服务或移动端应用系统的作用。通过推理系统,可以将深度学习模型部署到云(Cloud)端或者边缘(Edge)端,并服务和处理用户的请求。模型训练过程好比是传统软件工程中的代码开发的过程,而开发完的代码势必要打包,部署给用户使用,那么推理系统就负责应对模型部署和服务生命周期中遇到的挑战和问题。
当推理系统将完成训练的模型进行部署和服务时,需要考虑设计和提供模型压缩,负载均衡,请求调度,加速优化,多副本和生命周期管理等支持。相比深度学习框架等为训练而设计的系统,推理系统不仅关注低延迟,高吞吐,可靠性等设计目标,同时受到资源,服务等级协议(Service-Level Agreement),功耗等约束。
推理系统的作用可以理解为提供一个服务,服务的形式可以是 C/S 架构,也可以是微服务架构;服务的内容可以是推荐系统,也可以各种生成式模型。因此,系统的输入应通过 HTTP 或 gRPC 等请求发送,输出则根据业务需要进行定义。
推理系统需要考虑:
-
低延迟 满足服务等级的延迟
-
高吞吐 暴增负载的吞吐需求
-
高效率 高效率,低功耗
-
扩展性 支持不断增长的用户或设备
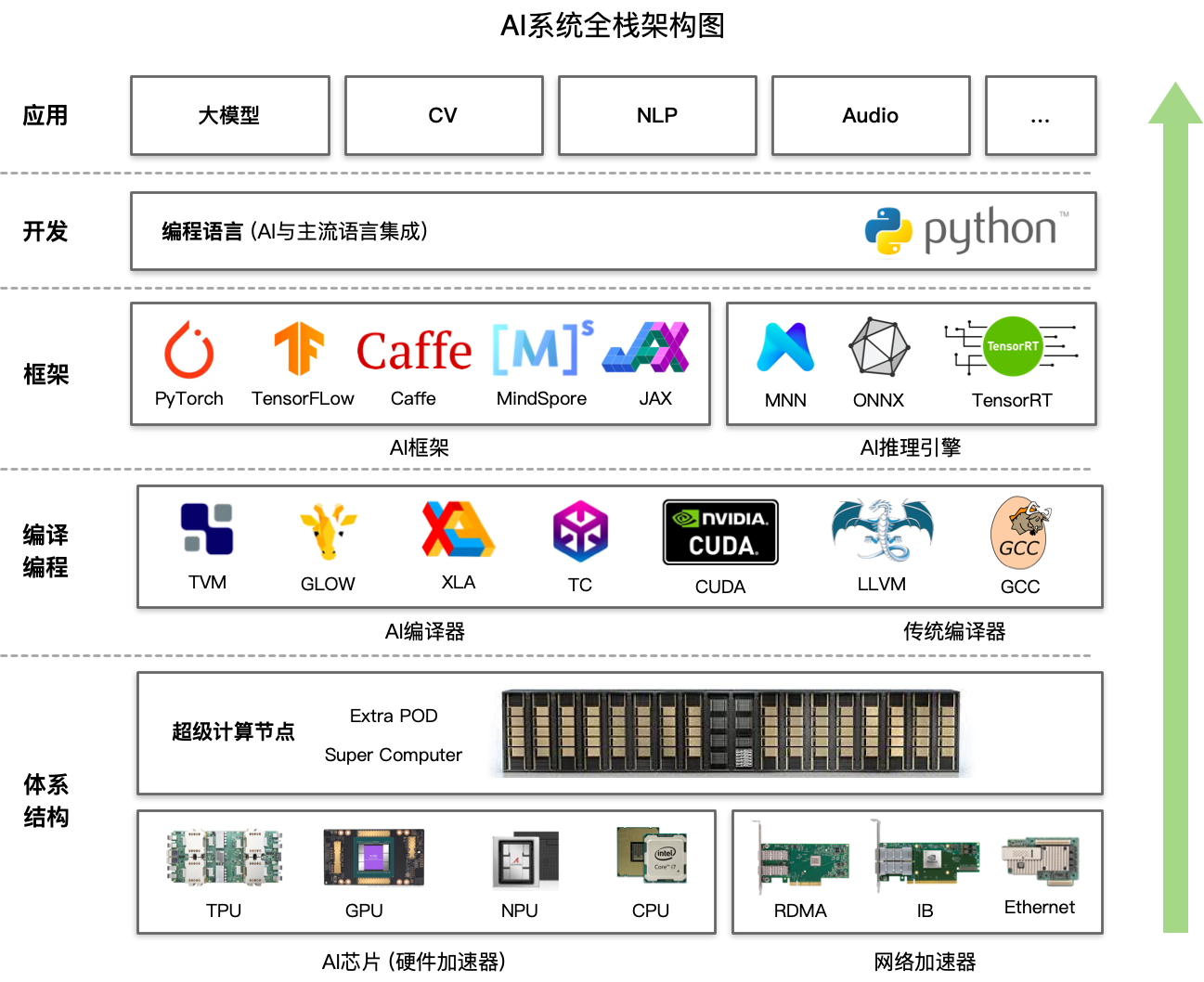
下图是推荐系统的架构图,请求响应与处理、监控和调度队列应该是高性能系统的常见组成部分,而推理系统的关键在于模型管理和推理引擎。

模型管理可以选择合适的 AI 模型执行推理任务,推理引擎则将各个任务合理分配给各种处理单元(GPU、DCU、CPU)进行处理。
推理引擎
推理系统与推理引擎
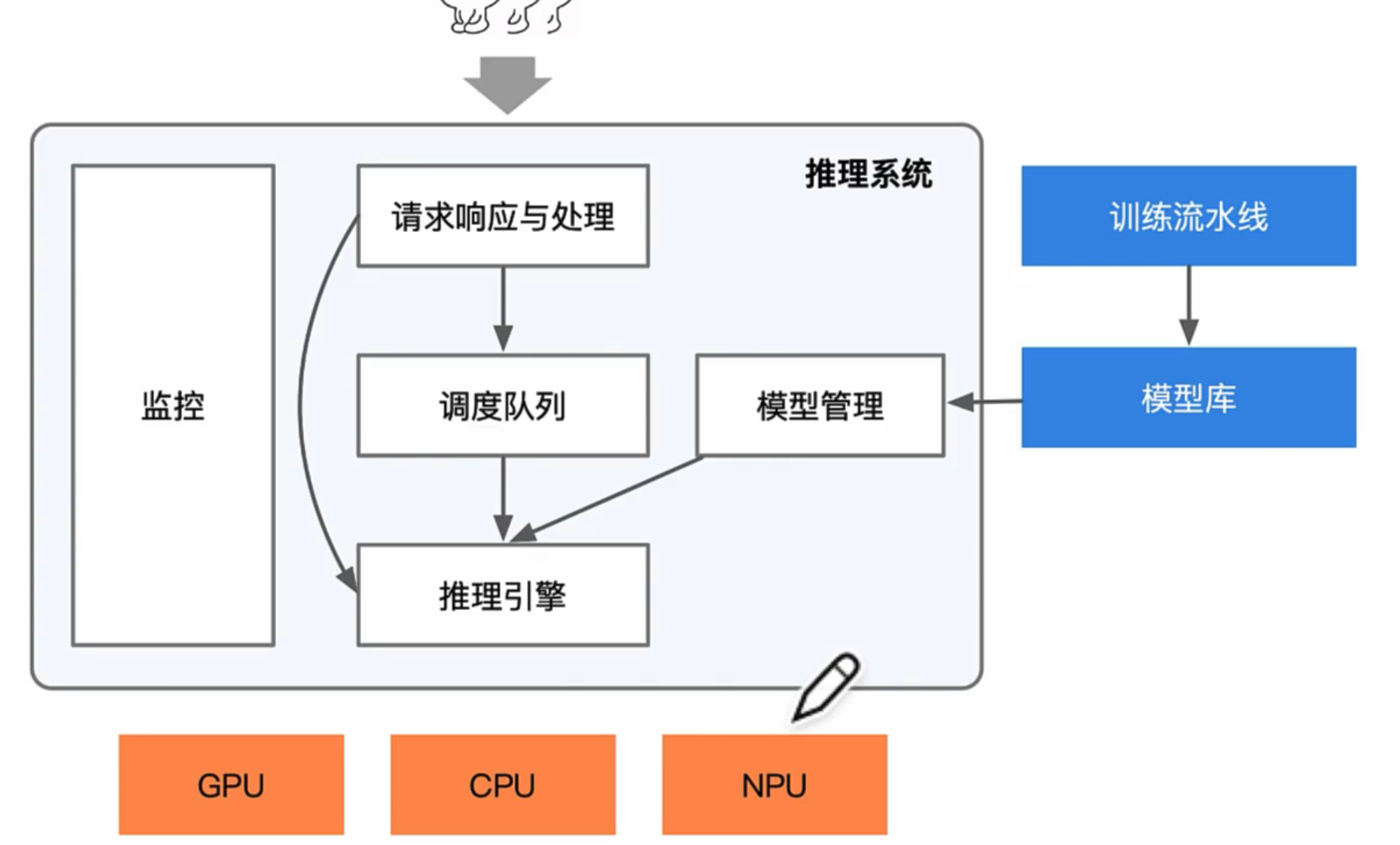
推理系统根据选取的模型选择对应的后端推理引擎,推理引擎会进行模型转换,通过一定策略对模型进行推理优化,提供模型运行时,以及提供对应的高性能算子。
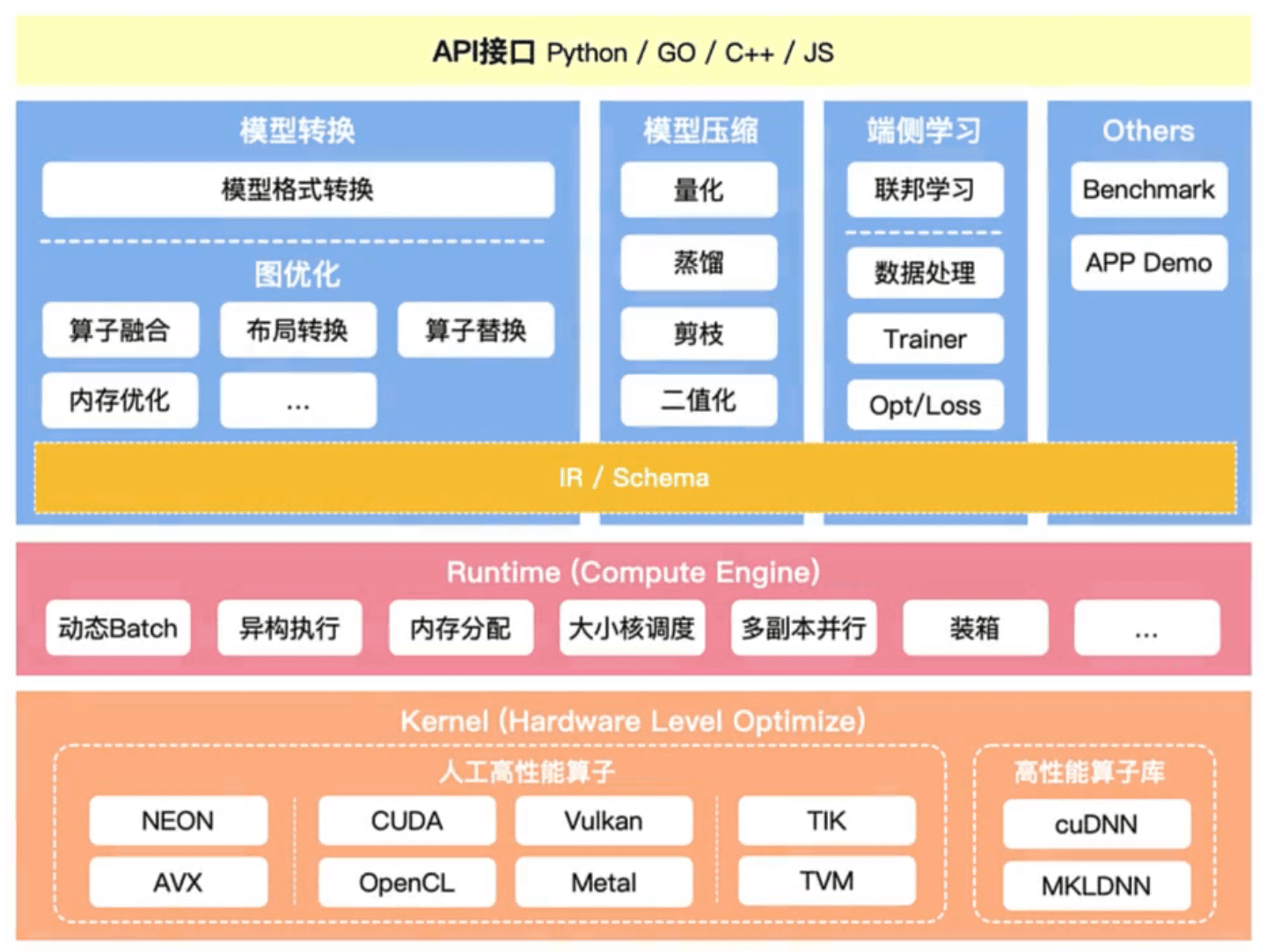
推理优化
推理引擎常常可以通过以下几个方向进行模型推理的延迟优化:
-
模型优化,降低访存开销:
-
层(Layer)间融合(Fusion)或张量(Tensor)融合
-
目标后端自动调优
-
内存分配策略调优
-
-
降低一定的准确度,进而降低计算量,最终降低延迟:
-
低精度推理与精度校准(Precision Calibration)
-
模型压缩(Model Compression)
-
-
自适应批尺寸(Batch Size):动态调整需要进行推理的输入数据数量
-
缓存(Caching)结果:复用已推理的结果或特征数据
常见的推理优化库:
DeepSpeed-Inference
微软推出的DeepSpeed库的推理方案,通过推理定制内核和MoQ量化方法缩小模型并降低生产时的推理成本,为使用 DeepSpeed、Megatron 和 HuggingFace 训练的基于兼容 Transformer 的模型提供无缝推理模式。
Accelerate
Hugginface 推出的针对大模型的分布式并行优化解决方案,可简化分布式训练和推理过程。Accelerate集成了DeepSpeed的一些功能(DeepSpeed ZeRO)以实现推理阶段的性能优化。
注:DeepSpeed 和 Accelerate也可为训练阶段提供加速优化。
推理部署
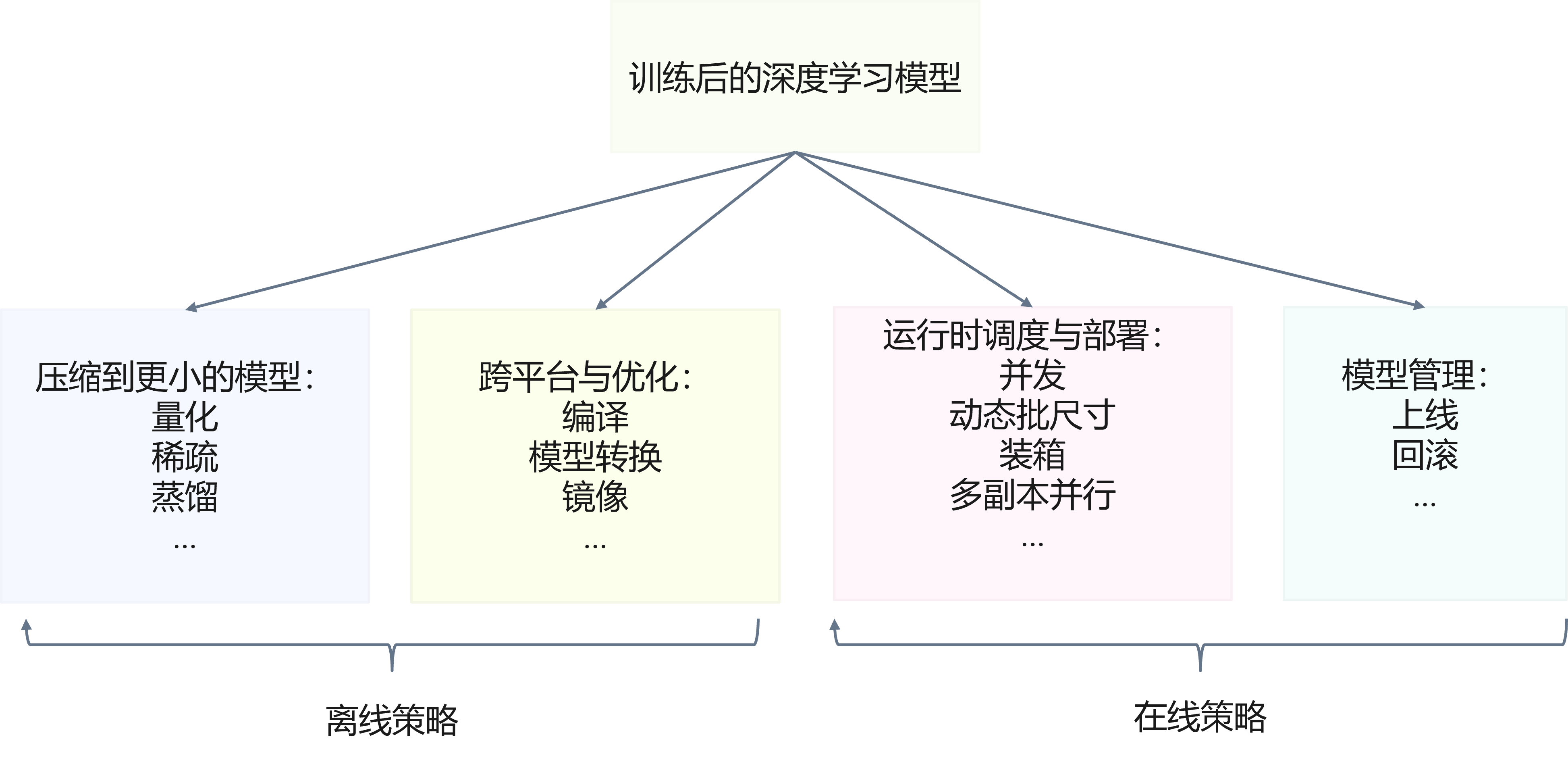
与训练阶段不同,推理部署需要对模型进行转换,使得模型能够在落地时有更好的性能表现,并且不依赖于特定的python运行时环境,每个部署格式都需要对应的推理引擎或者运行时环境。
模型转换与开放协议
模型可以通过**中间表达(IR)和相应的对应框架的模型解析器(Parser)**和对应框架的模型发射器(Emitter)实现跨框架转换。
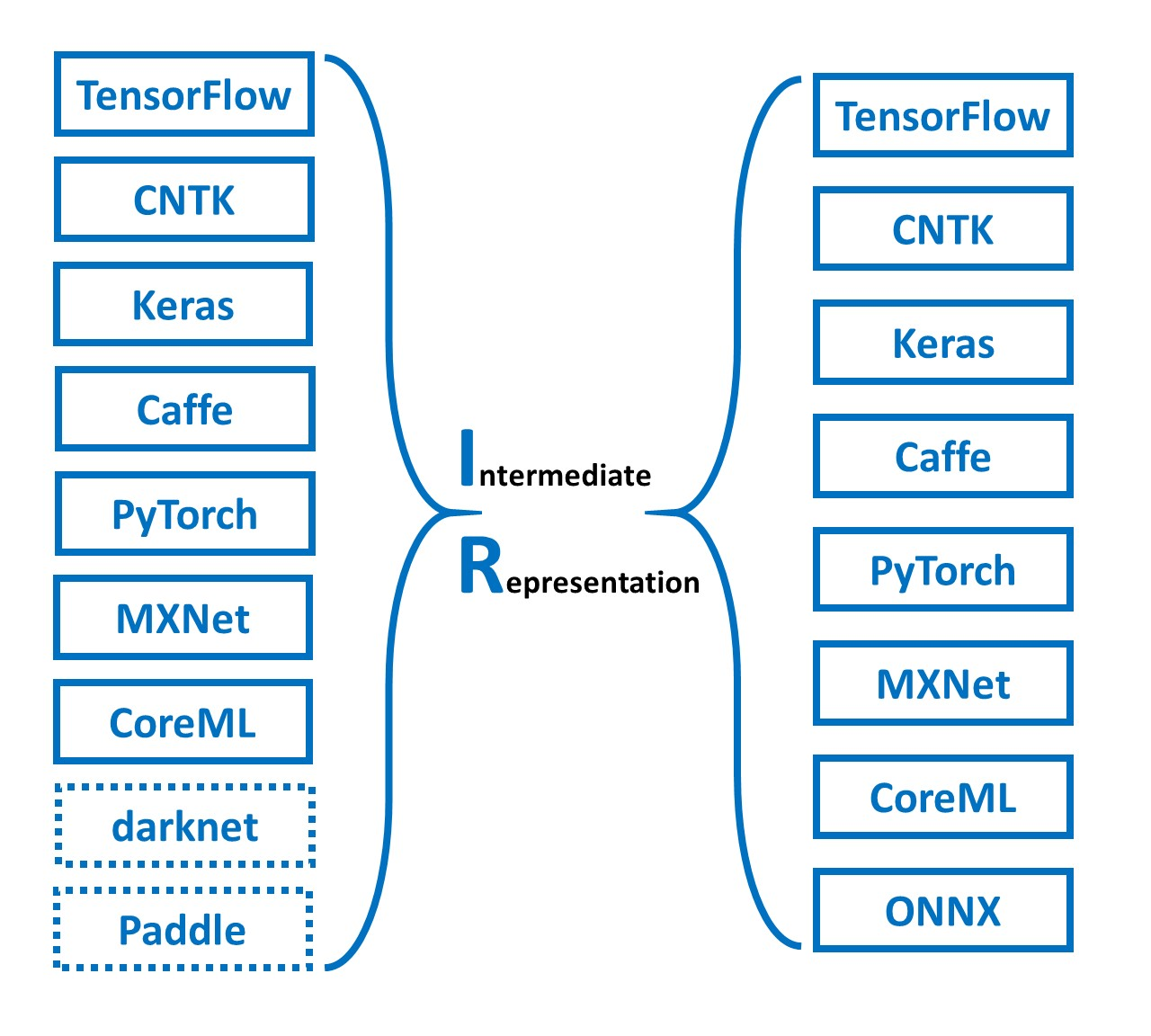
不同的深度学习框架都有自己的IR,通过IR的形式可实现跨框架的模型训练和推理。如某模型文件是通过 TensorFlow 训练的,通过该方式进行模型转换, 就能使用PyTorch 对其进行迁移学习微调。
常见的模型部署格式
TorchScript Module
使用Torch Script导出,Torch Script为PyTorch模型的中间表示形式, 是 Pytorch 的一个高性能子集,PyTorch JIT 编译器会对模型的计算执行运行时优化,也可以在 C++ 等高性能环境中运行。
Tensorflow SavedModel
包含一个完整的 TensorFlow 程序,包括训练的参数和计算。它不需要原始模型构建代码就可以运行,因此,对于使用 TFLite、TensorFlow.js、TensorFlow Serving 或 TensorFlow Hub 共享或部署非常有用。
ONNX
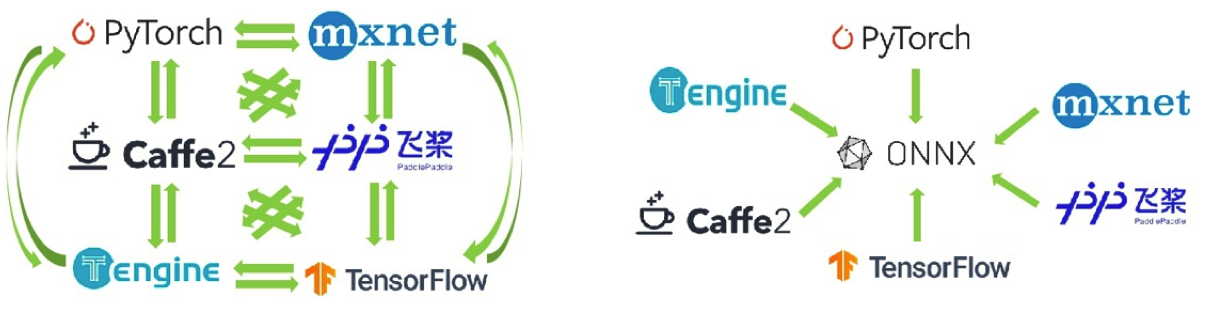
ONNX 是一种开放格式,旨在表示机器学习模型。ONNX 定义了一组通用运算符(机器学习和深度学习模型的构建块)和通用文件格式,使 AI 开发人员能够将模型与各种框架、工具、运行时和编译器结合使用。其对应的推理引擎为Onnx Runtime。
TensorRT
TensorRT是可以在NVIDIA各种GPU硬件平台下运行的一个C++推理框架。Pytorch、TF或者其他框架训练好的模型,可以转化为TensorRT的格式,然后利用TensorRT推理引擎去运行。
PaddlePaddle
PaddlePaddle 用于推理的模型,通过动态图与静态图或高层API保存,也可通过 X2Paddle 工具将pytorch模型转换为 PadddlePaddle 格式。其对应的推理引擎为PaddleInference,此外还有移动端推理引擎Paddle Lite和前端推理引擎Paddle.js。
OpenVINO
是英特尔推出的一款全面的工具套件OpenVINO的专有格式,OpenVINO的IR,可以完全利用其全部功能。可以由TensorFlow、PyTorch、MXNet、Caffe、Kaldi等模型转换而来,一般用于CPU部署。
除此之外,大部分的推理服务器还支持使用Python + Python runtime推理,如pytorch的Eager模式,也就是使用Pythonic的编程方式。
推理服务化
可靠性(Reliability)和可扩展性(Scalability)
通过底层的部署平台(例如,Kubernetes)的支持,用户可以通过配置方便地描述和自动部署多个推理服务的副本,并通过部署前端负载均衡服务达到负载均衡,进而达到高扩展性提升了吞吐量,同时更多的副本也使得推理服务有了更高的可靠性。
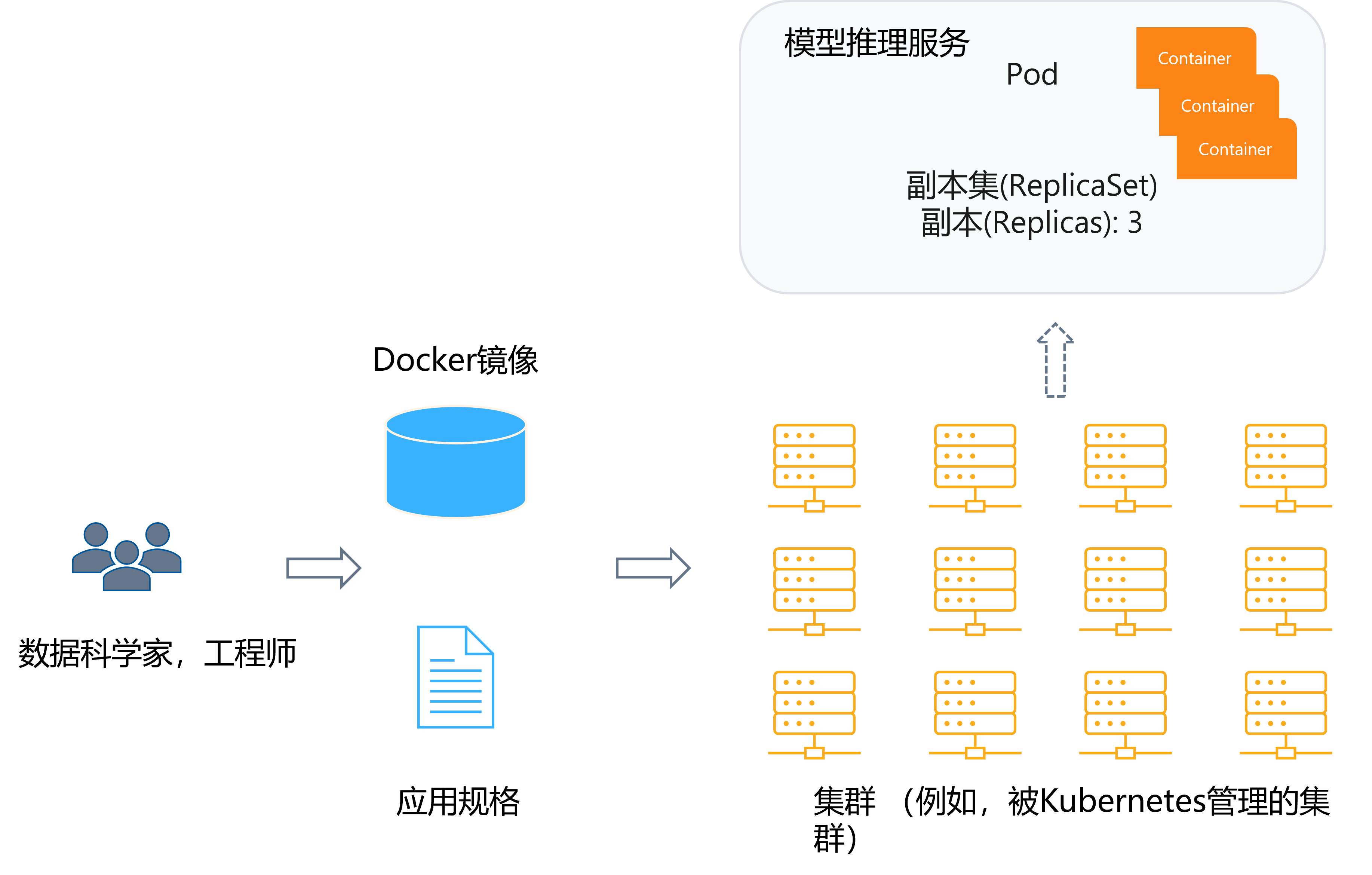
部署灵活性
训练的过程中模型使用的框架类型和版本多样,推理系统需要支持多样的深度学习框架所保存的模型文件,并和其他系统服务进行交互。在部署模型后,整个推理的流水线需要做一定的数据处理或者多模型融合,推理系统也需要支持与不同语言接口和不同逻辑的应用结合。
为了提供部署灵活性,推理系统提供了以下解决方法:
-
深度学习模型开放协议:通过 ONNX 等模型开放协议和工具,将不同框架的模型进行通过标准协议转换,优化和部署。
- 跨框架模型转换。
-
接口抽象:将模型文件封装并提供特定语言的调用接口。
-
提供构建不同应用逻辑的灵活性。
-
提供不同框架的通用抽象。
-
-
远程过程调用(Remote Procedure Call):可以将不同的模型或数据处理模块封装为微服务,通过远程过程调用(RPC)进行推理流水线构建。
- 跨语言,远程过程调用。
-
镜像和容器技术:通过镜像技术解决多版本与部署资源隔离问题。
- 运行时环境依赖与资源隔离。
常用的推理服务
-
服务端推理系统
-
Triton Inference Server:Nvidia发布的高性能推理服务器,支持多种推理引擎后端,够部署来自多个深度学习和机器学习框架的 AI 模型,包括 TensorRT、TensorFlow、PyTorch、ONNX、OpenVINO、Python、RAPIDS FIL 等。
-
TensorFlow Serving(TFX):专为生产环境而设计灵活、高性能的机器学习模型推理,对基于 TensorFlow 训练的模型原生支持较好,同时工具链完善,经过多年考验较为成熟。
-
Multi-model-server:aws推出的针对模型部署的模型服务器,可以做到跨机器学习框架。HTTP Server部分基于Java服务框架Netty实现,server部分性能和C++实现基本对齐。但是推理计算时直接调用相应运行框架的python接口,不如C++接口高效。另外,用户需要自定义预处理,推理,后处理handler。虽然一方面增加了灵活性,支持跨平台特性,但是易用性不足。
-
TorchServe:一种高性能、灵活且易于使用的工具,用于在生产中服务和扩展 PyTorch 模型。基于Multi-model-server框架添加了针对Torch的特性发展而来,对基于 PyTorch 训练的模型原生支持较好。
-
DJL-Serving:基于Deep Java Library的高性能服务系统,提供多引擎支持,支持包括PyTorch TorchScript 、TensorFlow SavedModel、MXNet、ONNX、TensorRT等模型的推理,除此外还支持Java和二进制推理。
-
针对LLM的推理服务
Deepspeed-MII
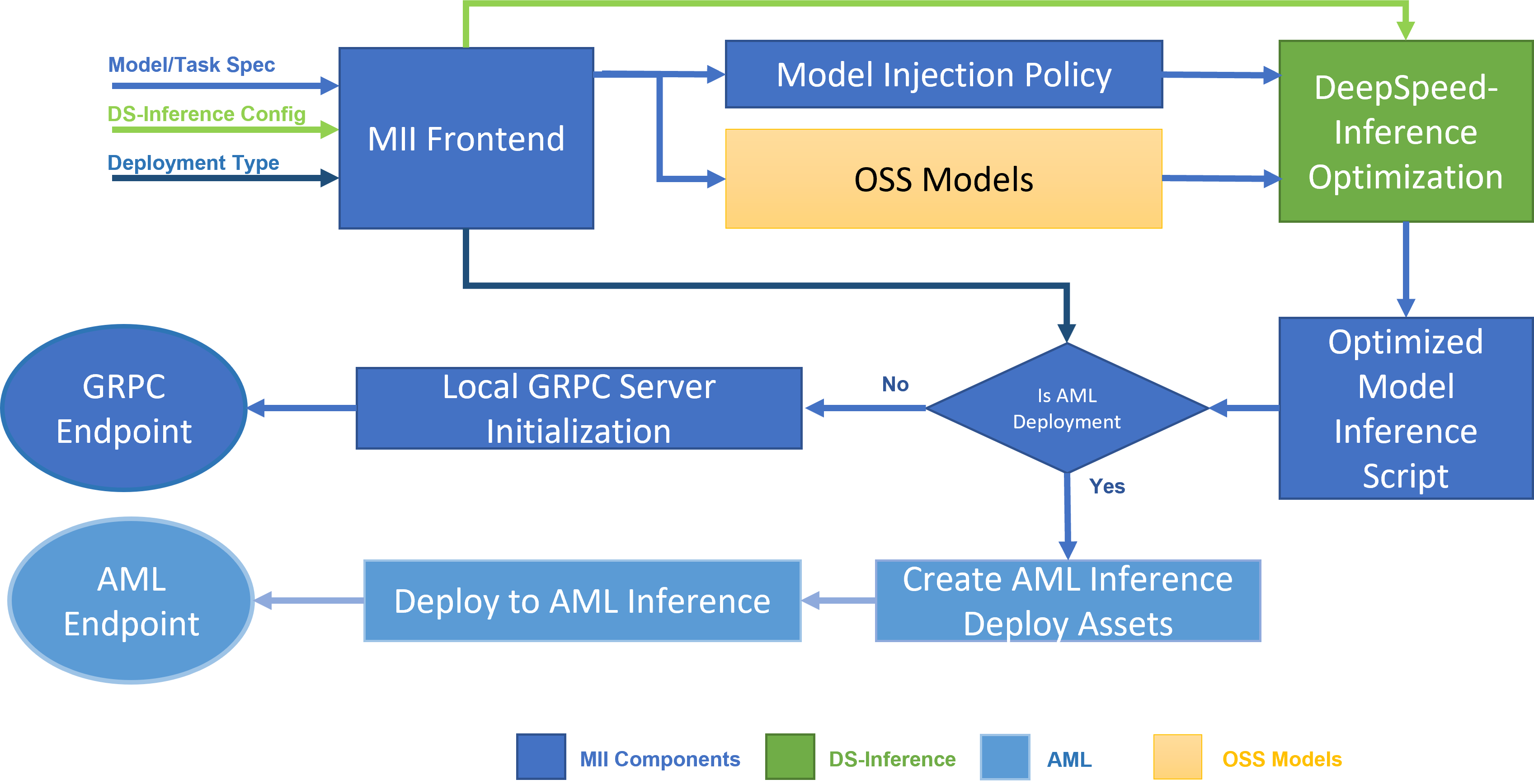
由 DeepSpeed 设计的开源 Python 库,旨在实现强大的模型推理大众化,底层由DeepSpeed-Inference提供支持,重点关注高吞吐量、低延迟和成本效益。除了语言模型之外,还支持加速text2image 模型,例如 Stable Diffusion。
vLLM
vLLM 是一个快速且易于使用的 LLM 推理和服务库,无缝支持许多 Hugging Face 模型。vLLM提供一系列的LLM推理优化策略,同时可以部署为 LLM 服务,通过HTTP对外提供服务。除此之外,vLLM 可以部署为模仿 OpenAI API 协议的服务器。vLLM可以单独部署,docker容器部署,也可以与Triton一起部署。
text-generation-inference(TGI)
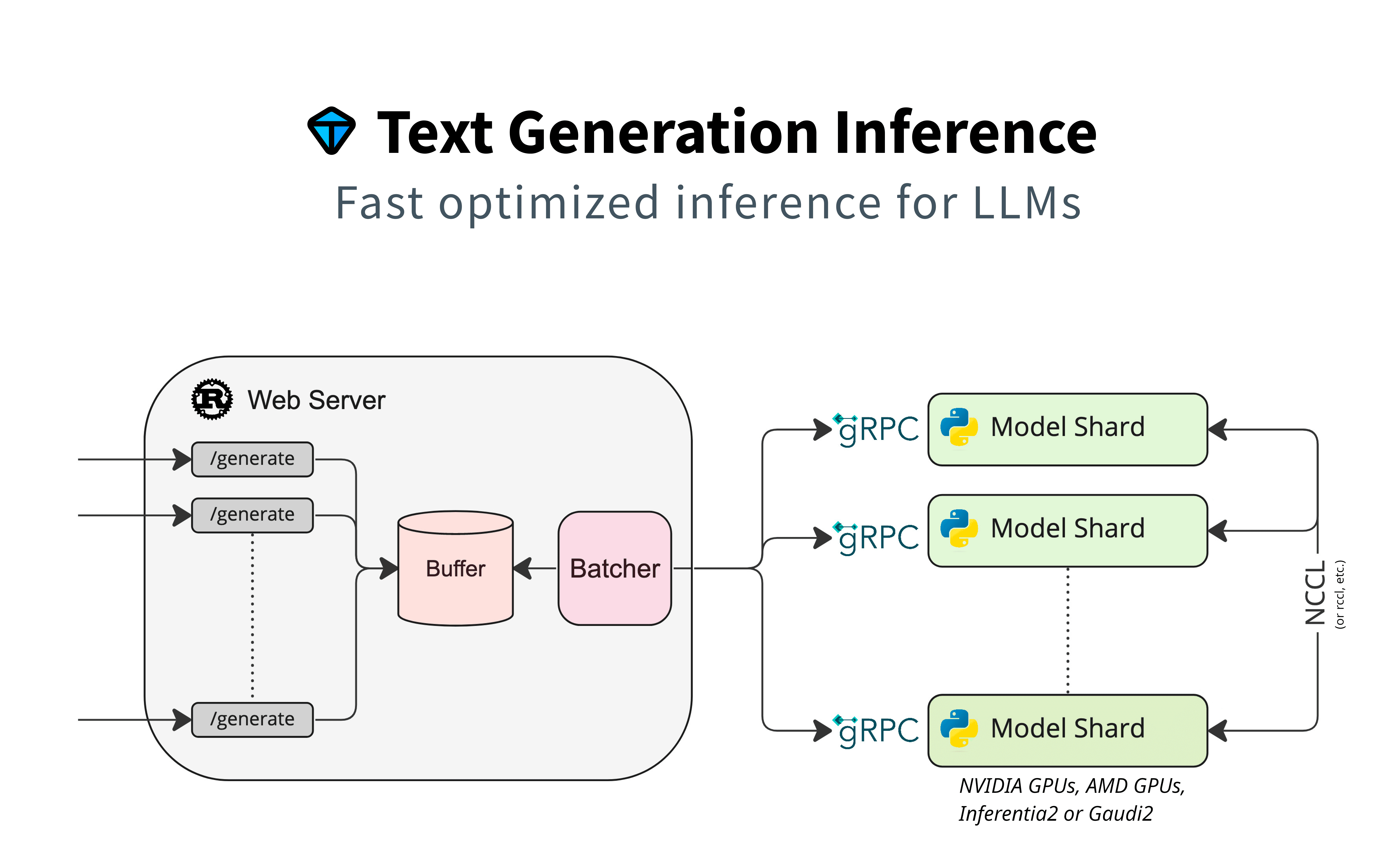
文本生成推理 (TGI) 是一个用于部署和提供大型语言模型 (LLM) 服务的工具包,包含了大量的LLM优化方法和CUDA内核支持,同时支持利用针对特定任务的微调来实现更高的准确性和性能。借助Dynamic Batching技术,TGI的模型服务能力(QPS)可达Faster Transformer的两倍以上,即使Faster Transformer的算子优化做的更好,并且可以提供更高的模型吞吐量。
OpenLLM
PPL LLM Serving
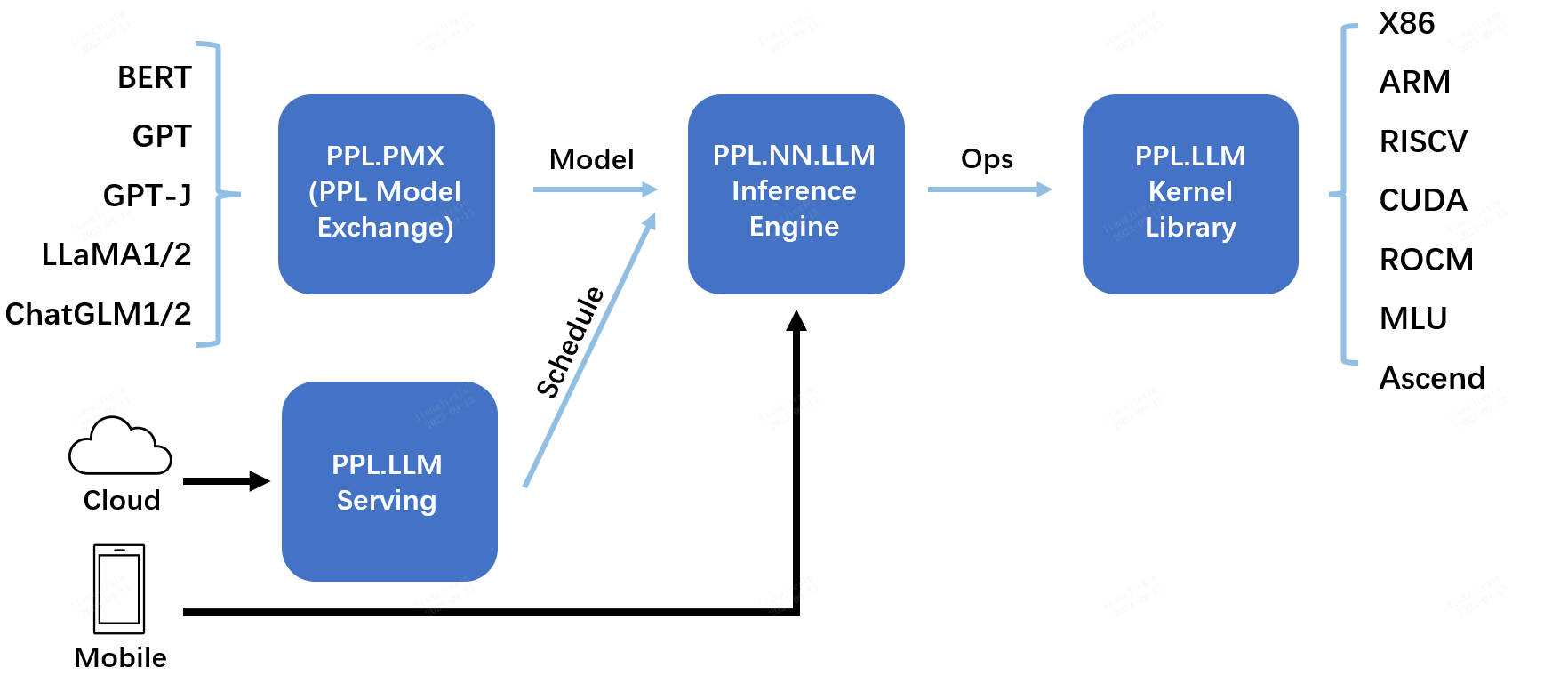
汤商科技推出的模型服务器,适用于各种大型语言模型 (LLM)。包含一个基于 gRPC 的服务器专为大语言模型设计的自研高性能推理引擎。
三、推理服务解决方案
Kubeflow/K-Serve
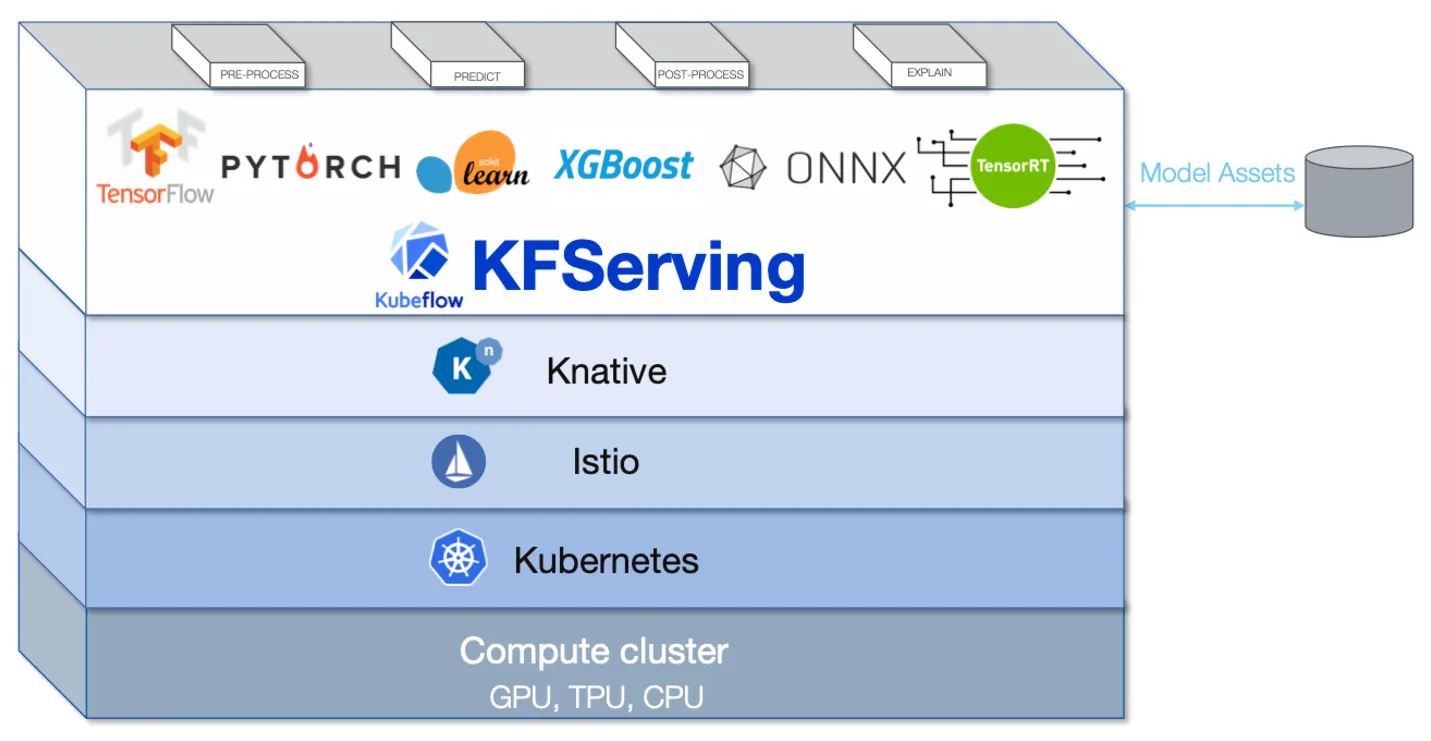
K-Serve是Kubeflow社区提供的构建在Kubernetes之上的推理服务解决方案。
K-Serve支持Tensorflow, Triton, XGBoost, SKLearn, ONNX, Pytorch等预置的模型服务器,同时也支持用户自定义服务器,因此K-Serve可以支持所有主流机器学习模型的服务部署。
Seldon Core
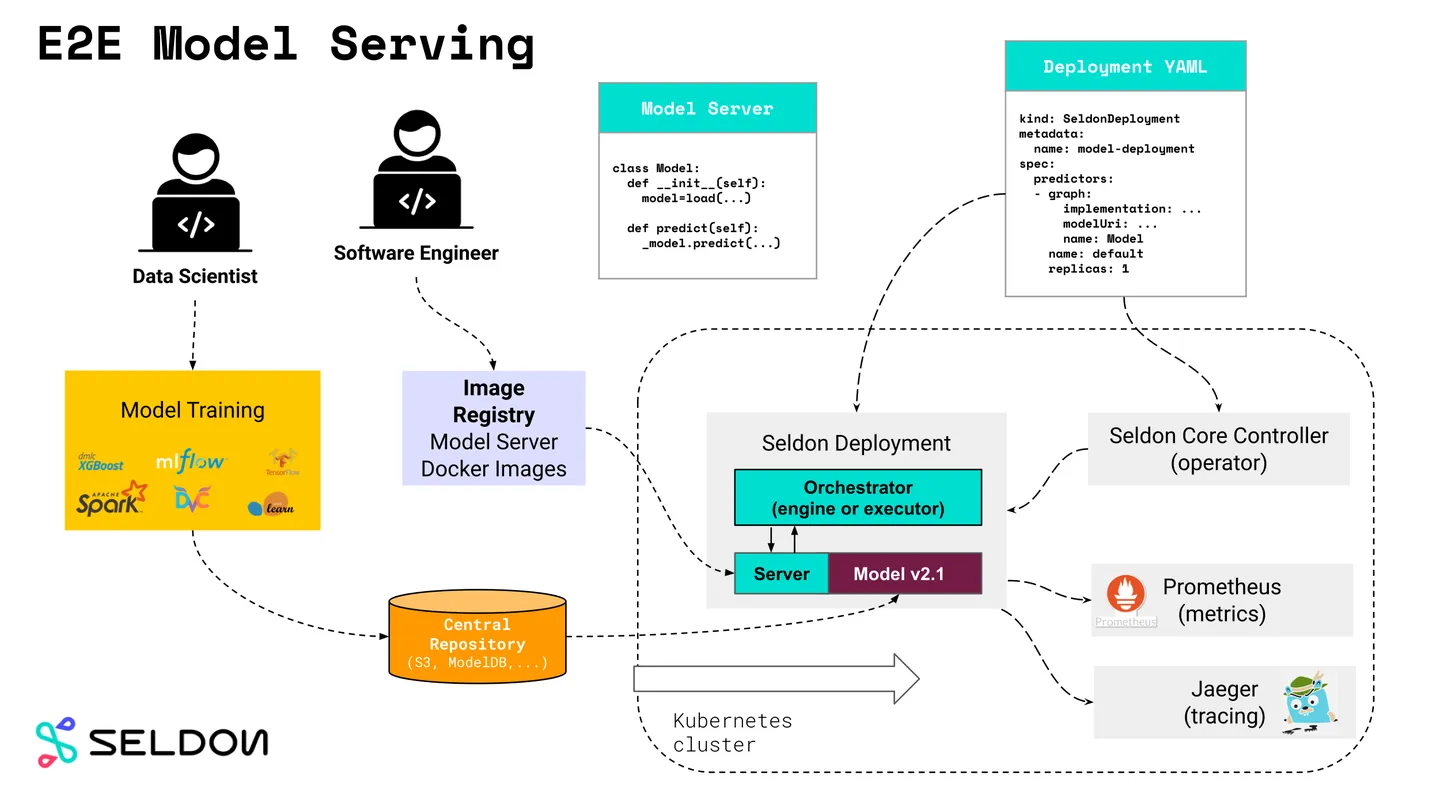
Seldon Core目前是在 Kubernetes 上运行机器学习推理负载方面最受欢迎的项目之一,是构建在Kubernetes上的机器学习模型部署的一整套解决方案。
Seldon Core有很多预装备的模型服务器,如TF-Serving Server, Triton Server, XGBoost Server, SKLearn Server等。Seldon Core也支持用户自定义Server,扩展性好。通过这种机制,Seldon Core可以支持所有主流的机器学习模型的部署。



