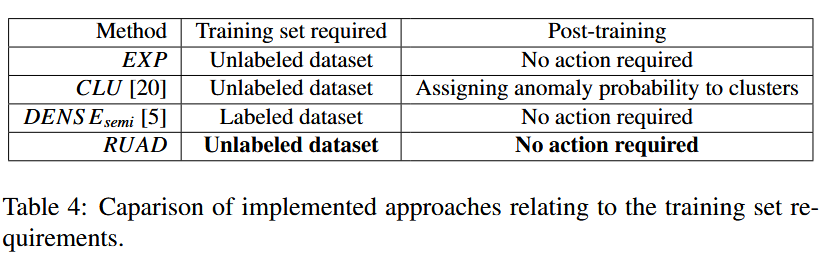
基于《The Complete Guide to Building Skills for Claude》及 Skill Authoring Best Practices 整理。本文面向手动编写 Skill 的开发者——你直接写 SKILL.md、手动测试、手动迭代,涵盖 YAML frontmatter、正文写作、目录结构、分发共享等完整知识。
]]><blockquote>
<p>基于《The Complete Guide to Building Skills for Claude》及 Skill Authoring Best Practices 整理。本文面向<strong>手动编写 Skill</strong> 的开发者HPC系统中基于粗粒度聚类和细粒度模型共享的有效节点级异常检测https://www.aweisite.top/posts/38d8733a.html2025-07-28T20:55:00.000Z2026-06-11T09:31:37.278Z摘要
我们提出了一种完全无监督的异常检测方法( RUAD ),该方法利用异常很少的事实,并通过使用自编码器网络中的LSTM单元显式地考虑数据中的时间依赖关系。由此产生的深度学习模型优于先前最先进的半监督方法[ 5 ],基于时间不感知的自动编码器网络。在本文提出和分析的数据集(采集自Marconi100超级计算机)上,前一种方法取得了0.7470的曲线下面积( ACU )测试集得分。相比之下,我们的无监督方法取得了最好的测试集AUC得分为0.7672。据我们所知,这项工作是首次将这种方法应用于HPC系统监控和异常检测领域
我们对我们的方法进行了非常大规模的实验评估。我们对Marconi100的980 +个节点分别训练了4种不同的深度学习模型。据我们所知,这是在HPC系统中有关异常检测的最大规模的实验,无论是考虑的节点数还是时间长度。先前的工作仅在观测时间(以文献为例,仅对HPC系统的20个节点进行了两个月的分析)较短的节点子集上评估模型。模型的逐节点训练也证明了面向大型HPC系统的逐节点模型的可行性。在单个NVIDIA Volta V100 GPU上,单个模型的训练时间小于30分钟。
为了避免选择特定的阈值$$T$$,我们引入了接收者-操作者特征曲线( Receiver- operator characteristic curve,ROC曲线)作为性能指标。它允许我们评估所有可能的决策阈值的分类方法的性能[ 51 ]。接受者-操作者特征曲线绘制了真阳性率与假阳性率的关系。随机决策表示两者之间的线性关系- -对于一个分类器来说要有意义,ROC曲线需要在对角线上方。对于曲线上的每个特定点,ROC曲线位于另一曲线上方的分类器为较好的分类器。分类器的整体性能可以用ROC曲线下的面积( Area Under the ROC Curve,AUC )来定量计算;一个做出随机决策的分类器的AUC等于0.5。AUC得分低于0.5的指定分类器比随机选择差。最好可能的AUC分数是1,这是通过一个分类器实现的,它将实现真阳性率等于1,同时具有0 (从广义上讲,这只能在微不足道的数据集或非常简单的学习任务上实现)的假阳性率。
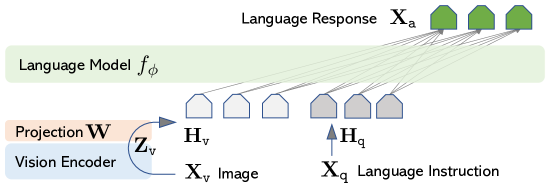
语言模型会在推理的过程中为所有输入token生成下一个token的分布,这允许模型为每个token采样一个后续token。比如输入序列为<bos> the cat sat,对于其中的每个token,可能会生成下面的预测yes、orange、saw 、down,每个后继token本身对于序列前缀来说都是一个合理的下一个token。
首先,我们知道Masked Self-attention的权重为如下所示的形式
Attention在经过Mask后,只有一部分被保留。也就是下面右图中的左上部分。
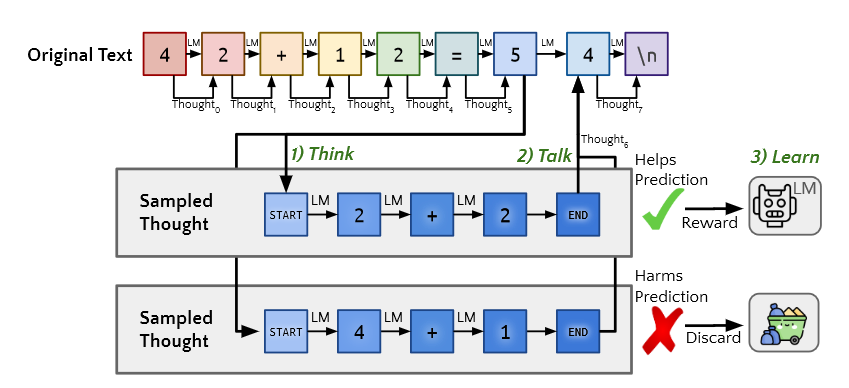
Quiet-STaR缓存每个前向传递的结果,将一个对角线注意力掩码串接到前一个注意力掩码上,每个生成的想法token只需要计算用于它与生成它路径token的注意力,以及和它自己的注意力,而不需要计算其他路径上token的注意力。如图所示,如果我们输入序列为a b c d,即序列长度n=4,理由采样数量r为1,那么会产生n×r=4个想法通路,每个想法通路的长度为t(t>2)。
这个过程一共需要得到$$n × r = 4$个token序列,直接按照原来的attention计算方式会对每个通路进行单独计算,这会带来计算量的浪费。然而,我们可以缓存a->b->c->d 的生成路径,于是便可以直接得到a' b' c' d'四个token(因为a'和b都是a生成token的候选),这样就分别得到了a、b、c、d第一个thought的第一个token。然后,我们通过计算a b c d序列的masked self-attention,它们和a' b' c' d'的masked atttion,以及a' b' c' d'各自对自身的self-attention,就得到了上面右侧的三个矩阵。对于a的第一个想法路径,其下一个应该是a'',它需要计算的是a a'的masked self-attention,它恰好可以由上面的三个矩阵的一部分拼接而成。
在并行生成思考时,模型同时从序列的每个位置生成多个思考序列,这些序列与真实序列之间没有直接对应关系,模型无法根据这些生成的序列与真实序列间的差异来更新模型参数。比如对于原始输入序列the cat sat on the mat. ,对于token cat 模型可能会生成下面几个理性思考:Because it is an animal.、Because it is a pet.、Because it is mentioned in the text.。 这些理性思考序列是并行生成的,没有明确的“正确”答案,因为多个理性思考序列都可能合理解释下一个token的出现,传统的反向传播方法就无法直接应用。
]]><h1>Quiet-STaR:让语言模型在“说话”前思考</h1>
<p>论文: <a href="https://arxiv.org/abs/2403.09629"> [arxiv 2403.09629]Quiet-STaR- Language Models Can Teach机器学习笔记——EM算法https://www.aweisite.top/posts/f511c36f.html2024-10-08T20:52:00.000Z2026-06-11T09:31:37.286ZEM(期望最大,Expectation-Maximization)算法是一种常用的迭代优化算法,通常用于含有隐变量或不完全数据的问题中,旨在估计模型的参数,使得对观测数据的对数似然函数达到最大化。它广泛应用于混合高斯模型(GMM)、隐马尔可夫模型(HMM)、协同过滤等问题中。
EM算法的基本思想
EM 算法通过迭代地执行两个步骤:
E 步(期望步,Expectation Step):在当前参数的基础上,计算隐含变量的期望值。
M 步(最大化步,Maximization Step):给定隐含变量的期望值,最大化似然函数,重新估计模型参数。
这个过程会在 E 步和 M 步之间反复迭代,直到模型的参数收敛到一个局部最优解。
EM算法的核心步骤
假设我们有一些带有隐变量的数据,数据的联合分布为 P(X,Z∣θ),其中:
X 是观测数据(可见数据)。
Z 是隐变量(隐藏数据)。
θ 是模型的参数,我们希望通过 EM 算法来估计这些参数。
EM 算法的目标是通过最大化对观测数据的似然函数来估计参数:
L(θ)=P(X∣θ)=Z∑P(X,Z∣θ)
由于隐变量 Z 的存在,直接求解对数似然比较复杂,因此通过 EM 算法来迭代优化。具体步骤如下:
1. 初始化:
首先,我们对参数 θ 进行初始化。这些初始值可以随机选取或通过某些启发式方法得到。
2. E 步(期望步):
在 E 步中,给定当前模型参数 θ(t),计算隐变量的条件期望。直观上讲,这一步是计算在当前参数下,隐变量 Z 的可能取值。具体而言,E 步计算的是后验分布:
Q(θ∣θ(t))=EZ∣X,θ(t)[logP(X,Z∣θ)]
这相当于在当前参数 θ(t) 下,给定观测数据 X,计算 Z 的期望值,从而得到一个新的目标函数 Q(θ) 来表示。
3. M 步(最大化步):
在 M 步中,最大化步骤是通过更新参数 θ 来最大化上一步中计算得到的 Q(θ∣θ(t)):
θ(t+1)=argθmaxQ(θ∣θ(t))
这一优化过程可以被视为是寻找使得期望似然函数最大的参数。
4. 迭代过程:
重复执行 E 步和 M 步,直到参数 θ 的变化足够小(即达到某个收敛条件),或者对数似然函数的改进趋于停止。
]]><p>EM(期望最大,Expectation-Maximization)算法是一种常用的迭代优化算法,通常用于含有<strong>隐变量</strong>或<strong>不完全数据</strong>的问题中,旨在估计模型的参数,使得对观测数据的对数似然函数达到最大化。它广泛应用Tree Of Thoughts 解读https://www.aweisite.top/posts/dc4a249.html2024-07-31T16:35:00.000Z2026-06-11T09:31:37.282Z1. 思维链(Chain Of Thought)
( a ) 独立地对每个状态赋值:V(pθ,S)(s)∼pθvalue(v∣s)∀s∈S ,其中V 是评估函数,S 是当前需要评估的一组状态,pθvalue(v∣s) 表示在给定状态 s 的条件下,生成评估值 v 的概率分布。V评估状态s,以产生一个标量值v (如1 ~ 10)或一个分类(如确定/可能/不可能)。
( b )跨状态投票:V(pθ,S)(s)=1[s=s∗] ,通过投票机制选出一个最优状态 s∗∼pθvote(s∗∣S),然后评估每个状态 s。如果某个状态 s 等于最优状态 s∗,则该状态的评估值为 1;否则评估值为 0。这种方法用于识别和选择最有希望的状态进行进一步探索。
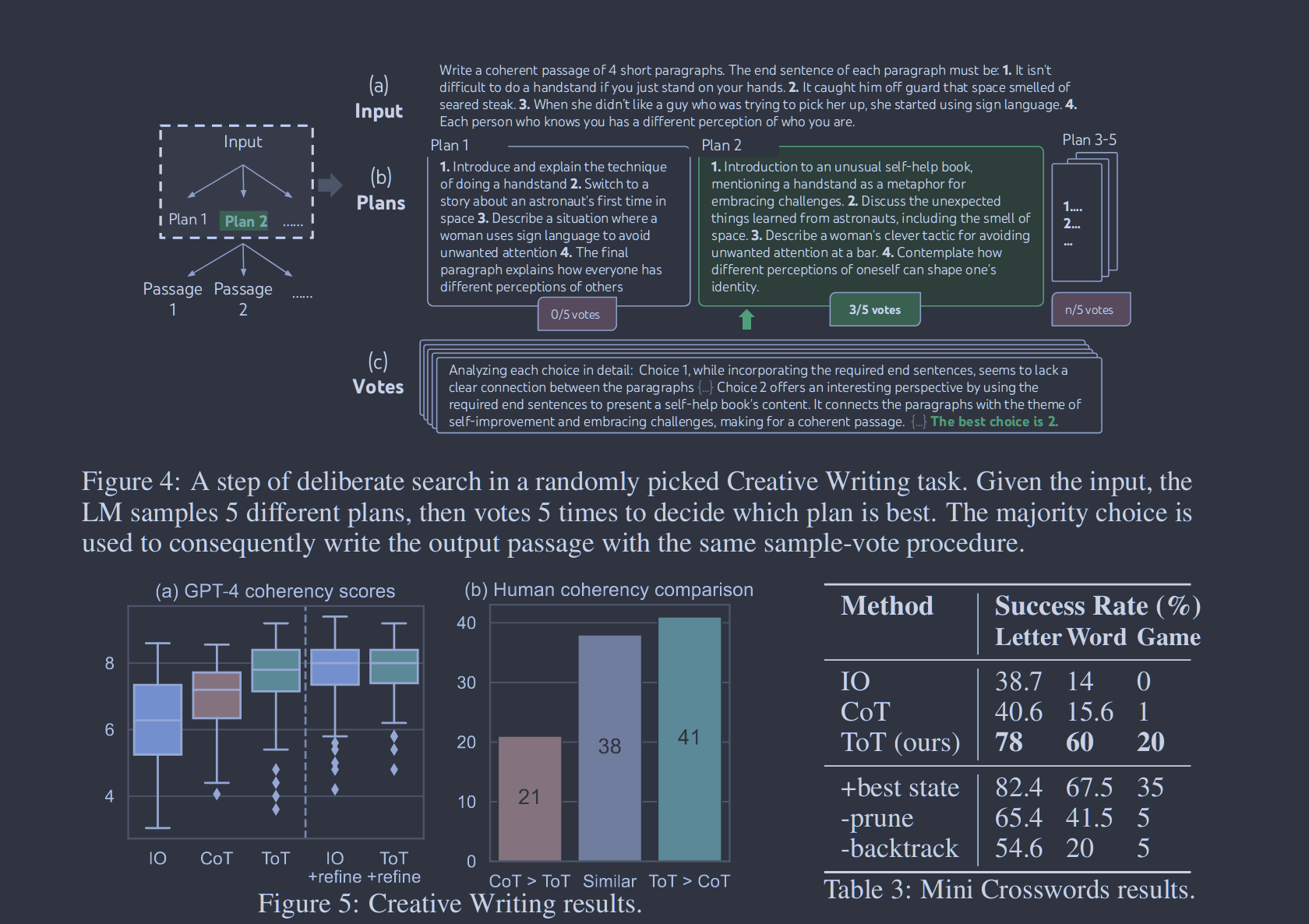
在创造性写作中使用的是跨状态的投票,其提示词如下。
1 2 3 4
vote_prompt = '''Given an instruction and several choices, decide which choice is most promising. Analyze each choice in detail, then conclude in the last line "The best choice is {s}", where s the integer id of the choice. ''' compare_prompt = '''Briefly analyze the coherency of the following two passages. Conclude in the last line "The more coherent passage is 1", "The more coherent passage is 2", or "The two passages are similarly coherent". ''
]]><h2 id="1-思维链(Chain-Of-Thought)">1. 思维链(Chain Of Thought)</h2>
<p>要介绍ToT,首先要介绍下大名鼎鼎的CoT,也就是<strong>思维链(Chain Of Thought)</strong>。</p>
<p><iTree of Thoughts: Deliberate Problem Solving with Large Language Modelshttps://www.aweisite.top/posts/55ae080b.html2024-07-28T16:18:00.000Z2026-06-11T09:31:37.282Z思维树:用大型语言模型深思熟虑地解决问题
摘要
语言模型越来越多地被用于跨广泛任务的一般问题解决,但在推理过程中仍然局限于令牌级别的、从左到右的决策过程。这意味着他们可能在需要探索的任务、战略前瞻或初始决策起关键作用的任务中落空。为了克服这些挑战,我们引入了一种新的语言模型推理框架- - "思维树" ( Tree of Thoughts,ToT ),它推广了流行的"思维链" ( Chain of Thoughts )方法来促进语言模型,并允许对文本( "思想")的连贯单元进行探索,作为问题解决的中间步骤。ToT允许LM进行深思熟虑的决策,通过考虑多条不同的推理路径和自我评估的选择来决定下一步的行动方向,并在必要时进行前瞻或回溯以做出全局选择。我们的实验表明,ToT显著提高了语言模型在3个需要非平凡计划或搜索的新颖任务上的问题解决能力:游戏24、创意写作和微型填字游戏。例如,在第24局的比赛中,有思维链提示的GPT-4只解决了4%的任务,而我们的方法取得了74%的成功率。所有提示的代码:https://github.com/ysymyth/tree-of-thought-llm.
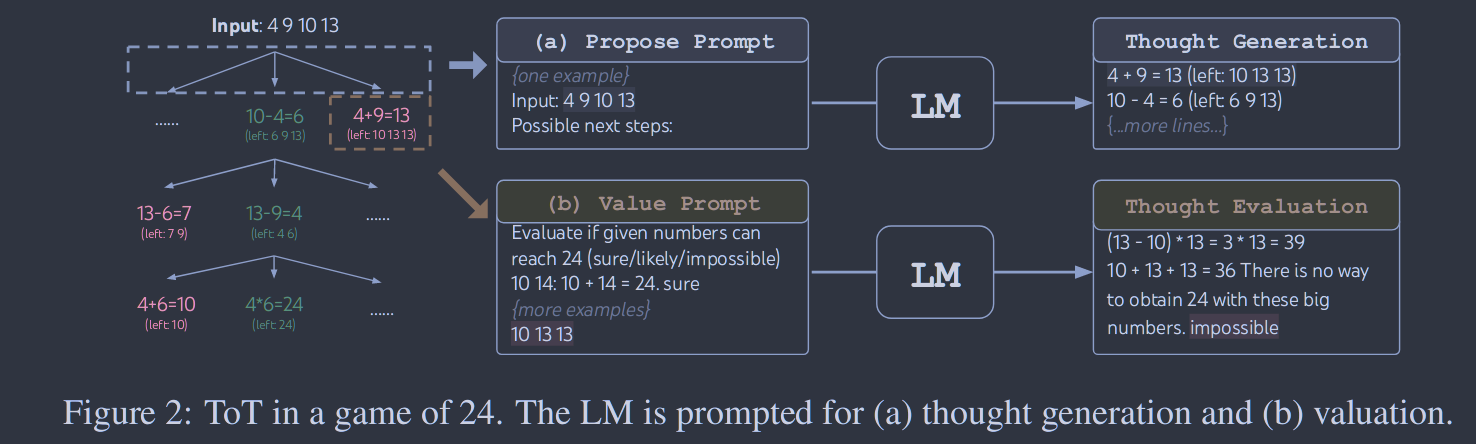
**3 .状态评估器V(pθ,S)。**给定一个不同状态的前沿面,状态评估器评估它们在解决问题上的进展,作为搜索算法的启发式,以确定哪些状态要继续探索,以何种顺序进行。虽然启发式是解决搜索问题的标准方法,但它们通常是预编程的( e.g. Deep Blue )或学习的(如AlphaGo)。我们提出了第三种选择,即利用LM有意地推理状态。在适用的情况下,这种深思熟虑的启发式可以比编程规则更灵活,比学习的模型更有效。与思想生成器类似,我们考虑两种策略来单独或共同评估状态:
( a ) 独立地对每个状态赋值:V(pθ,S)(s)∼pθvalue(v∣s)∀s∈S ,其中一个值提示关于状态s的理由,以产生一个标量值v (如1 ~ 10)或一个分类(如确定/可能/不可能),可以启发式地转换成一个值。这种评价性推理的基础可以因问题和思考步骤而异。在这项工作中,我们通过少量的前瞻性模拟(例如,快速确认5 , 5 , 14通过5 + 5 + 14可以达到24 ,或者' hot l '通过填充' e ' in '可以表示' inn ')和常识( ( 1 ) ( 2 ) ( 3 )太小,达不到24 ,或者没有词可以以" tzxc "开头)来探索评估。前者可能促进"好"状态,后者有助于消除"坏"状态。这样的估值不需要完美,只需要近似即可
( b )跨状态投票:V(pθ,S)(s)=1[s=s∗] ,其中一个"好"状态s∗∼pθvote(s∗∣S)是基于在投票提示符中刻意比较S中的不同状态而被投票出来的。当问题成功较难直接对( e.g.通道连贯性)进行赋值时,自然要对不同的局部解进行比较,并投票选出最有希望的局部解。这在精神上类似于一种"阶梯式"自洽策略,即把"探索哪种状态"作为多选QA,并使用LM样本对其进行投票。
任务设置。我们从randomwordgenerator.com中随机抽取句子组成100个输入,每个输入约束都没有真值段落。由于我们发现GPT-4可以在大部分时间内遵循输入约束,因此我们主要通过两种方式来评估篇章连贯性:使用GPT-4的零样本提示来提供1-10的标量分数,或者使用人工判断来比较不同方法的输出对。对于前者,我们采样了5个分数,并对每个任务的输出进行了平均,我们发现这5个分数通常是一致的,平均每个输出的标准差约为0.56。对于后者,我们在一项盲法研究中使用作者的一个子集来比较CoT vs. ToT生成通道对,其中通道的顺序在100个输入上随机翻转。
图2:( a ) Llama结构。( b ) Llama自回归模型。( c )三种常见的PEFT操作。所有可学习的成分都用红色突出显示,而冻结的成分用灰色突出显示。LoRA应用于所有的Query、Key和Value块。适配器针对的是FFN模块。Soft - Prompt侧重于调整每个解码器的输入激活。为了简单起见,我们只展示了一个解码器。
标准的完全微调需要大量的计算开销,并且可能会损害模型的泛化能力。为了缓解这个问题,一种广泛使用的方法是保持预训练的主干不变,只引入在模型架构中具有战略地位的最小数量的可训练参数。在对特定下游任务进行微调的同时,只更新这些额外模块或参数的权重,这将导致存储、内存和计算资源需求的大幅减少。由于这些技术具有增加参数的特点,这些技术可以被称为添加微调,如图4 ( a )所示。接下来,我们讨论了几种流行的Additive PEFT算法。
与加性PEFT通过增加更多的参数来增加模型复杂度不同,选择性PEFT对现有参数的子集进行微调,以增强模型在下游任务中的性能,如图4 ( b )所示。具体来说,给定一个含有参数θ={θ1,θ2,...,θn}的模型,其中每个θi表示一个单独的模型参数,n表示这些参数的总数,选择性PEFT的过程通过对这些参数施加一个二进制掩码M={m1,m2,...,mn}来表示。M中的每个mi要么为0,要么为1,表明相应的参数θi是选择(1)还是不选择(0)进行微调。微调后更新的参数集θ′由下式给出:
式中:α为缩放因子。在训练开始时,Wdown使用随机高斯分布初始化,而Wup初始化为零,以确保Wup最初保持为零的值。LoRA的实现非常简单,并且已经在具有高达1750亿参数的模型上进行了评估。图8 ( c )以单个解码器为例,冻结的和可学习的成分分别用灰色和红色突出。一旦微调完成,LoRA的自适应权重与预训练的骨干权重无缝集成。这种整合保证了LoRA保持了模型的效率,在推理过程中不会增加额外的负担。
在LoRA训练中,选择合适的秩一直是一个具有挑战性的问题。为了解决这个问题,DyLoRA [ 171 ],如图8 ( b )所示,在预定义的训练预算范围内对LoRA模块进行一系列秩的训练,而不是坚持单一的固定秩。具体来说,对于给定的秩范围R=rmin,rmin+1,...,rmax,DyLoRA在训练过程的每一次迭代中动态地选择一个秩r∈R。因此,矩阵Wdown和Wup被裁剪为选定的秩r,从而产生截断版本Wdown↓r=Wdown[1:r,:]和Wup↓r=Wup[:,1:r],并且在此迭代过程中,后续的前向和后向传递将被限制在Wdown↓r和Wup↓r上,而不是Wdown和Wup。通过这种动态和免搜索的方法,DyLoRA显著减少了为特定任务寻找最优和固定的LoRA秩所需的训练时间。AdaLoRA [ 217 ]用奇异值分解( Singular Value Decomposition,SVD )重新计算了△W,记为△W=P∧Q,其中P∈Rd×r且Q∈Rr×k是正交矩阵,∧是包含奇异值{λi}1≤i≤r的对角矩阵。所有的三个权重矩阵都是可学习的。在训练过程中,奇异值根据其重要性得分进行迭代剪枝,这些奇异值是由梯度权重乘积大小的移动平均值构造的。为了保证P和Q之间的正交性,即PTP=QQT=I,在损失函数中加入了一个额外的正则项:
对于Diff-Pruning III - B这样的任务,与Bitfit和Adapter稍有不同。对于Diff - Pruning,关于共享权重和"差异"的计算是分开进行的。然后将结果相加,即
Xt×(W=δt)=Xt×W+Xtδt
这里,W表示骨干模型权重,δt表示剪枝后的权重,可表示为Sparse MVM。
图13:协调分批( CB )策略
PetS提出的另一个挑战是如何调度不同的PEFT请求以实现高性能。PetS调度器通过两级调度策略实现高并行性:如图13所示,协调批处理( CB )和宏批处理流( MS )。通过CB,输入查询将首先根据它们的输入长度进行聚类,然后根据它们的共享算子进行分组。这是为了确保在不浪费填充的情况下执行相同序列长度的查询。MS策略将协同批处理后的分组查询与不同操作符的理论延迟以及系统建模参数一起生成最佳执行顺序。
D.平行PEFT训练框架
a )设计挑战:与PetS系统旨在容纳灵活的多PEFT算法不同,SLoRA [ 158 ]和Punica [ 19 ]只专注于为各种任务提供多个LoRA块。设计多个PEFT培训系统在两个主要方面提出了关键挑战:
C )多租户PEFT设计:为Punica框架中的多租户PEFT模型设计一个高效的系统,重点解决几个关键的挑战,以最大化硬件利用率和最小化资源消耗。该系统旨在将服务于工作负载的多租户LoRA整合到尽可能小的GPU集合上。这种合并是通过将用户请求策略性地调度给已经在服务或训练LoRA模型的活动GPU来实现的,从而提高GPU利用率。对于较旧的请求,Punica周期性地迁移它们以进一步合并工作负载,从而为新的请求腾出GPU资源。它融入了LoRA模型权重的按需加载,只引入毫秒级的延迟。该特性使Punica可以灵活地将用户请求动态地合并到一组小的GPU上,而不受那些已经在这些GPU上运行的特定LoRA模型的限制。此外,Punica指出解码阶段是模型服务成本的主要因素,Punica的设计主要集中在优化解码阶段的性能。模型服务的其他方面利用简单的技术,如按需加载LoRA模型权重,以有效地管理资源利用率。
]]><p>索引术语- -大型语言模型、参数高效微调、计算机系统、分布式系统。</p>
<p>原文链接: <a href="https://arxiv.org/abs/2403.14608">Parameter-Efficient Fine-Tuning for Large Model模型推理服务https://www.aweisite.top/posts/477823d7.html2024-01-17T11:22:00.000Z2026-06-11T09:31:37.286Z一、推理服务概述
**推理系统(Inference System)**是用于部署人工智能模型,执行推理预测任务的人工智能系统,类似传统 Web 服务或移动端应用系统的作用。通过推理系统,可以将深度学习模型部署到云(Cloud)端或者边缘(Edge)端,并服务和处理用户的请求。模型训练过程好比是传统软件工程中的代码开发的过程,而开发完的代码势必要打包,部署给用户使用,那么推理系统就负责应对模型部署和服务生命周期中遇到的挑战和问题。
from modelscope import AutoModelForCausalLM, AutoTokenizer from transformers import pipeline import deepspeed import os import torch from djl_python import Input, Output
情感分析( SA )旨在根据输入文本检测对给定目标的情感极性。SA可以分为显式SA ( ESA )和隐式SA ( ISA ),其中前者是当前的主流任务,其情感表达显式地出现在文本( Pontiki et al , 2014)中。与ESA不同,ISA更具有挑战性,因为ISA中的输入只包含事实描述,而没有直接给出( Russo et al , 2015)的显式意见表达。例如,给定一个没有显著线索词的文本'Try the tandoori salmon! ',几乎所有现有的情感分类器都对'the tandoori salmon'预测中性极性。人类可以很容易地准确地判断文本的情感状态,因为我们总能把握文本背后的真实意图或观点。因此,如果不真正理解情绪是如何被唤起的,传统的SA方法对ISA是无效的。
事实上,首先发现隐藏的意见情境对于实现准确的ISA是至关重要的。对于图1中的显性案例# 1,它不容易捕捉到整体的情感图片(例如, "环境"是方面, "伟大"是意见),因此可以精确地推断对给定目标酒店的正极性。受这种细粒度情感精神(薛峰、李晓萍, 2018 ;张杰等, 2021 ; Xu et al , 2020)的启发,我们考虑挖掘隐含的方面和观点状态。对于图1中的隐式情况#2,如果一个模型可以首先推断关键的情感成分,例如,潜在的方面"味道",潜在的意见"好的和值得尝试",那么最终极性的推断可以大大缓解。为了达到这个目标,常识推理(也就是说,推断什么是'tandoori salmon')和多跳推理(即,先推断出方面,然后再推断出意见)的能力是必不可少的。
幸运的是,最近预训练大规模语言模型( LLMs )的巨大成功提供了一个很有前途的解决方案。一方面,LLMs被发现携带着非常丰富的世界知识,表现出非凡的常识理解能力( Paranjape et al , 2021 ; Liu et al , 2022)。另一方面,最新的思维链( CoT )思想揭示了LMs的多跳推理( Wei et al . , 2022 ; Zhou et al , 2022 ;张杰等, 2023)的巨大潜力,其中带有一些提示的LLM可以出色地进行链式推理。在所有这些成功的基础上,本文实现了一个面向ISA的三跳推理CoT框架( THOR )。在LLM的基础上,我们设计了3个提示语进行3步推理,每个提示语分别推断1 )给定目标的细粒度方面,2 )对该方面的潜在观点,3 )最终的极性。通过这种由易到难的增量推理,可以一步一步地引出整体情感图片的隐藏上下文,从而更容易地实现最终极性的预测,有效地缓解了任务预测的困难。
SA (无论是ESA还是ISA)的任务定义为:给定一个带有目标项 t⊂X 的句子 X ,模型确定对 t 的情感极性 y ,即积极、中性或消极。我们使用带有提示的现成LLM来解决任务。对于标准的基于提示的方法,我们可以构造如下的提示模板作为LLM的输入:
给定句子X,对t的情感极性是什么?
LLM应通过(y=argmaxp(y∣X,t))f返回答案。
2.1 思维链提示
现在考虑CoT式提示( Wei et al . , 2022 ; Fu et al , 2022)方法进行多步推理。在我们的THOR( cf.图2)中,我们并不是直接询问LLM关于 y 的最终结果,而是希望LLM在回答 y 的最终结果之前推断潜在的方面和观点信息。这里我们定义了中间方面项 a 和潜在意见表达 o 。我们构造three-hop提示如下。
步骤1。我们首先询问LLM在下面的模板中提到了 α 的哪些方面:
C1[给定的句子X],t 的哪个具体方面可能被提及?
C1 是第一个hop的提示上下文。这个步骤可以表述为 A=argmaxp(a∣X,t) ,其中 A 是输出文本,明确提到了方面 a 。
步骤2。现在基于 X ,t 和 a ,我们要求LLM详细回答关于 a 的潜在观点是什么:
C2[ C1 , A]。基于常识,对于t的上述方面,隐含的看法是什么,以及为什么?
C2 是连接 C1 和 A 的第二个hop提示语境,这一步可以写成 O=argmaxp(o∣X,t,a) ,其中 O 是包含可能意见表达 o 的答案文本。
步骤3。以完整的情感骨架( X , t , a和o)为上下文,最后请LLM推理出极性t的最终答案:
C3[ C2 , O]。基于这种观点,什么是对t的情感极性?
C3 为第三提示语境。记这一步为 ( y_\hat = argmaxp( y | X , t , a , o) ) 。
2. 通过自洽增强推理
我们进一步利用自洽机制( Wang et al. , 2022b ; Li et al., 2022b)来巩固推理的正确性。具体来说,对于3个推理步骤中的每一个步骤,我们设置LLM解码器来生成多个答案,每个答案都可能给出方面 a 、观点 o 和极性 y 的不同预测。在每一步中,保留那些推断 a ,o 或 y 的投票一致性高的答案。我们选择置信度最高的那个作为下一步的上下文。
2.3 有监督的推理修正
我们还可以在按需训练集可用的情况下对THOR进行微调,即有监督的微调设置。我们设计了一种推理修正方法。技术上,在每个步骤中,我们通过连接 1)初始上下文,2)本步骤的推理答案文本和 3)最终问题来构建提示,并将其输入LLM来预测情感标签,而不是去进行下一步的推理。例如,在步骤-1的最后,我们可以组装一个提示:[ C1 , A , "对t的情感极性是什么? "]。在金标签的监督中,LLM会被教导产生更多正确的中间推理,有助于最终的预测。
表1:有监督微调设置下的F1结果。最好的结果用粗体标出。表1中带"的模型得分复制自Li et al. ( 2021 )。
3. 实验
设置 我们在基准的Sem Eval14 Laptop和Restaurant数据集( Pontiki et al , 2014)上进行实验,其中所有的实例都按照Li等( 2021 )的方法分为显式情感和隐式情感。由于编码器风格的BERT不能生成支持CoT的文本,我们使用编码器-解码器风格的FlanT52作为我们的主干LLM。我们还用GPT3 (布朗等, 2020)和ChatGPT ( Ouyang et al , 2022)进行了测试。我们使用了Flan - T5的四个版本:250M ( base ),780M ( large ),3B ( xl )和11B ( xxl ),以及GPT3的四个版本:350M,1.3B,6.7 B和175B。注意,GPT3没有发布模型参数,我们通过API以提示的方式使用。这也意味着我们无法用GPT3进行有监督的微调。我们与目前表现最好的基线进行了比较,包括:BERT + SPC ( Devlin et al , 2019),BERT + ADA ( Rietzler et al , 2020),BERT + RGAT ( Wang et al , 2020),BERTAsp + CEPT ( Li et al , 2021),BERT + ISAIV ( Wang et al , 2022a)和BERTAsp + SCAPT ( Li et al , 2021)。我们同时考虑有监督的微调和零样本设置。我们采用F1作为评价指标。在小样本设置下,我们通过它们的源代码重新实现了基线。我们的实验在4块NVIDIA A100 GPU上进行。
不同模型尺寸对Llms的影响 在表1和表2中,我们看到了使用(非常)大LLM的功效。在图3中,我们研究了不同LLM尺度的影响。我们看到,随着模型规模的增大,我们的多跳推理提示的功效呈指数级放大。这与已有的CoT提示方法( Wei et al . , 2022 ; Zhou et al , 2022 ; Fu et al , 2022)的发现非常吻合,即LM越大,CoT的改善效果越显著。因为当LLM足够大时,常识推理和多跳推理的能力得到了极大的发展和加强。
用Thor改进Chatgpt ChatGPT的最新诞生带来了NLP和AI社区的革命性进步。在这里,我们比较了我们的THOR on GPT3 (175B)和ChatGPT的改进。图4给出了100个测试实例的测试结果。我们可以看到,两种LM在ESA上都表现出了非常高的性能,而THOR的增强效果非常有限。但是,基于提示的GPT3和ChatGPT在ISA上仍然失败很多,而我们的THOR在ISA上有了很大的改进。
情感分析长期以来一直是NLP社区( Pang和Lee , 2007 ; Dong et al . , 2014 ;施炳展等, 2022)的研究热点。虽然显式SA模型可以轻松地根据意见表达进行预测,但是由于隐式意见特征( Li et al , 2021 ; Wang et al , 2022a)的存在,使得隐式SA变得更加棘手。和在现实场景中,ISA往往更为普遍。尽管已经对ISA ( Li et al , 2021 ; Wang et al , 2022a)做出了努力,但现有的工作仍然可以局限于传统的推理范式。如前所述,ISA应该通过推理来解决,即常识和多跳推理。因此,本工作遵循这种直觉,以多跳推理机制解决ISA为目标。
作为SA的一个关键分支,细粒度SA已经得到了很好的探索( Wang et al. , 2017; Li et al, 201, 2022a)。细粒度情感分析的思想是将情感分析分解成若干个关键的情感要素,包括目标、方面、观点和情感极性,它们在细节( Peng et al. , 2020;Fei 等, 2022)上共同构成完整的情感图。这项工作吸取了同样的细粒度SA的精神。我们认为隐式情感的推理应该是一个渐进的过程,一步一步地推断出情感元素,最终以由易到难的方式理解情感极性。
语言模型预训练在增强下游应用(Raffel et al, 2020)的实用性方面受到了越来越多的研究关注。最近,大规模语言模型(LLMs)在人类智能方面表现出了巨大的潜力,例如ChatGPT (Ouyang et al, 2022)。LLMs已被广泛证明在常识理解(Paranjape et al, 2021;Liu et al,2022)和多跳推理(Wei et al.,2022;Zhou et al, 2022)上表现出非凡的能力。本文基于最新提出的思想链( CoT )思想,实现了基于LMs的隐式情感推理。CoT提示是一种无梯度的技术,它诱导大的LM产生中间推理步骤,从而得出最终的答案。Wei等人( 2022 )正式研究了语言模型中的CoT提示,他们诱导LM产生一系列连贯的中间推理步骤,这些步骤直接指向原始问题的最终答案。
]]><h1>用思想链提示推理隐式情感</h1>
<h2 id="摘要">摘要</h2>
<p>虽然情感分析系统试图根据输入文本中的关键观点表达来确定给定目标的情感极性,但在隐式情感分析(ISA)中,观点线索是以隐式和模糊的方式出现的。因此,检测隐式情感需要常识和多跳的推理能力来推断观Parameter-Efficient Transfer Learning for NLPhttps://www.aweisite.top/posts/798b9f4.html2023-11-29T17:30:00.000Z2026-06-11T09:31:37.278Z面向Nlp的参数高效迁移学习
从预训练的模型中迁移在许多NLP任务( Dai & Le , 2015 ; Howard & Ruder , 2018 ;雷德福et al , 2018)上都有很强的性能。BERT是一个在无监督损失的大型文本语料上训练的Transformer网络,在文本分类和抽取式问答( Devlin等, 2018)上取得了先进的性能。在本文中我们处理在线设置,其中任务到达一个流。目标是构建一个在所有任务上都表现良好的系统,但不为每个新任务训练一个全新的模型。
NLP中最常见的两种迁移学习技术是基于特征的迁移和微调。相反,我们提出了一种基于适配器模块(雷布菲等, 2017)的替代传输方法。基于特征的迁移涉及到预训练的实值嵌入向量。这些嵌入可能是词(米科洛夫等, 2013)、句( Cer et al , 2019),也可能是段落层面的( Le & Mikolov , 2014)。然后将这些嵌入信息传递给自定义的下游模型。微调包括从预训练的网络中复制权重,并在下游任务上进行微调。最近的工作表明,微调往往比基于特征的迁移(霍华德&鲁德, 2018)具有更好的性能。
我们实例化了基于适配器的文本转换器调优。这些模型在许多NLP任务中取得了先进的性能,包括翻译、抽取式问答和文本分类问题( Vaswani et al , 2017 ;Devlin et al , 2018 ; Devlin et al , 2018)。我们考虑Vaswani等( 2017 )提出的标准Transformer结构。
为了限制参数的数量,我们提出了瓶颈架构。适配器首先将原始的 d 维特征投影到一个更小的维度 m ,施加一个非线性,然后再投影回 d 维。每层增加的参数总数,包括偏差,为 2md+d+m。通过设置md ,我们限制了每个任务添加的参数数量;在实际操作中,我们使用了原模型参数的0.5-8%左右。瓶颈维度 m 提供了一种简单的方法来权衡性能和参数效率。适配器模块本身内部存在跳接。通过跳跃连接,如果投影层的参数初始化为近零,则模块初始化为近似恒等函数。
除了适配器模块中的层外,我们还在每个任务中训练新的层标准化参数。该技术类似于条件批归一化( De Vries et al , 2017)、FiLM (Perez等, 2018)和自调制( Chen et al. , 2019),同样可以实现网络的参数有效自适应;每层只有 2d 个参数。然而,仅训练层归一化参数不足以获得良好的性能,见3.4节。
3. 实验
我们展示出了适配器实现文本任务的参数高效传递。在GLUE基准(Wang et al. , 2018)上,适配器调优在BERT完全微调的0.4%以内,但仅增加了微调训练参数数量的3%。我们在进一步的17个公开分类任务和SQuAD问题回答上证实了这一结果。分析表明,基于适配器的调优自动聚焦于网络的高层。
3.1 实验设置
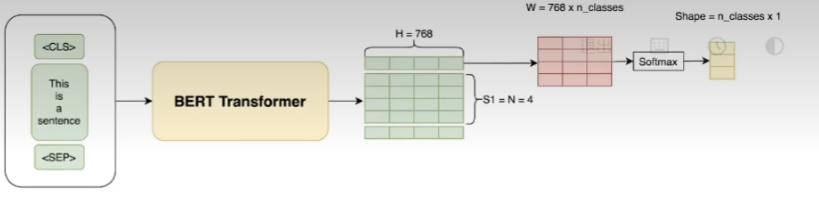
我们使用公开的、预训练的BERT Transformer网络作为我们的基础模型。为了使用BERT进行分类,我们遵循Devlin et al . ( 2018 )的方法。每个序列中的第一个标记是一个特殊的"分类标记"。我们在这个令牌的嵌入上附加一个线性层来预测类标签。
我们的训练过程也遵循Devlin et al( 2018 )。我们使用Adam ( Kingma & Ba , 2014)进行优化,其学习速率在前10%的步骤中线性增加,然后线性衰减到零。所有运行均在4个批处理大小为32的Google Cloud TPU上训练。对于每个数据集和算法,我们运行一个超参数扫描,根据验证集上的准确率选择最佳模型。对于GLUE任务,我们报告了提交网站提供的测试指标。对于其他分类任务,我们报告了测试集准确率。
预训练的文本表示 预训练的文本表示被广泛用于提高NLP任务的性能。这些表示在大型语料库(通常是无监督的)上进行训练,并作为特征输入到下游模型。在深度网络中,这些特征也可能在下游任务上进行微调。基于分布信息训练的布朗簇是预训练表示( Brown et al , 1992)的经典例子。Turian等人( 2010 )的研究表明,预训练的词嵌入比从零开始训练的词嵌入效果更好。自深度学习流行以来,词嵌入得到了广泛的应用,出现了许多训练策略( Mikolov et al . , 2013 ;Pennington et al . , 2014 ;Bojanowski et al . , 2017)。更长的文本、句子和段落的嵌入也被开发出来( Le & Mikolov , 2014 ; Kiros et al , 2015 ;科诺et al , 2017 ; Cer et al , 2019)。
微调 微调整个预训练模型已经成为一种流行的特征替代方法。在NLP中,上游模型通常是神经语言模型( Bengio et al , 2003)。通过对Transformer网络( Vaswani et al , 2017)和隐形语言模型损失( Devlin等, 2018)进行微调,在问答( Rajpurkar等, 2016)和文本分类( Wang et al . , 2018)上取得了最新的研究成果。抛开性能不谈,微调的一个优点是不需要任务特定的模型设计,不像基于表征的迁移。然而,初始精调确实需要为每一个新的任务设置一组新的网络权重。
多任务学习 多任务学习( MTL )是同时对任务进行训练。早期的工作表明,在任务间共享网络参数利用了任务的规律性,产生了改进的性能(Caruana、1997)。作者在网络的低层共享权重,并使用专门的高层。许多NLP系统已经开发了MTL。例如:文本处理系统(词性,组块,命名实体识别等。) (Collobert& Weston , 2008)、多语言模型( Huang et al . , 2013)、语义解析( Peng et al , 2017)、机器翻译(Johnson等, 2017)、问答( Choi et al , 2017)等。MTL产生一个单一的模型来解决所有问题。然而,与我们的适配器不同,MTL需要在训练过程中同时访问任务。
持续学习 作为同时训练、持续学习或终身学习的替代方法,学习旨在从一系列任务( Thrun , 1998)中学习。然而,当重新训练时,深度网络往往会忘记如何执行先前的任务;一个挑战被称为灾难性遗忘(McCloskey & Cohen , 1989 ;French, 1999)。已经提出了一些技术来减轻(Kirkpatrick et al , 2017 ; Zenke et al , 2017)的遗忘,然而,与适配器不同的是,存储器是不完善的。渐进网络通过为每个任务(Rusu 等, 2016)实例化一个新的网络"列"来避免遗忘。然而,参数的数量随着任务数量的增加而线性增长,因为适配器非常小,所以我们的模型具有更好的可扩展性。
视觉中的迁移学习 在构建图像识别模型( Yosinski et al , 2014 ; Huh等, 2016)时,在ImageNet ( Deng et al , 2009)上预训练的微调模型无处不在。该技术在许多视觉任务上获得了最先进的性能,包括分类(Kornblith等, 2018),细粒度分类(Hermans 等, 2017),分割( Long 等 , 2015)和检测( Girshick等, 2014)。在视觉方面,对卷积适配模块(Rebuffi et al , 2017 ; 2018 ; Rosenfeld & Tsotsos , 2018)进行了研究。这些工作通过在ResNet ( He et al , 2016)或VGG Net (Simonyan & Zisserman, 2014)中添加小卷积层来进行多域的增量学习。使用1 × 1卷积限制了适配器的大小,而原始网络通常使用3 × 3。这使得每个任务的整体模型大小增加了11 %。由于无法进一步减小核尺寸,因此必须使用其他权重压缩技术来进一步节省核尺寸。我们的瓶颈适配器可以小得多,并且仍然表现良好。
]]><h1>面向Nlp的参数高效迁移学习</h1>
<p>原始论文:《Parameter-Efficient Transfer Learning for NLP》
<a href="http://arxiv.org/abs/1902.00751">http://arxiv.org/aChain-of-Thought Prompting Elicits Reasoning in Large Language Modelshttps://www.aweisite.top/posts/c0250395.html2023-11-27T14:09:00.000Z2026-06-11T09:31:37.278Z思维链提示在大型语言模型中引发推理
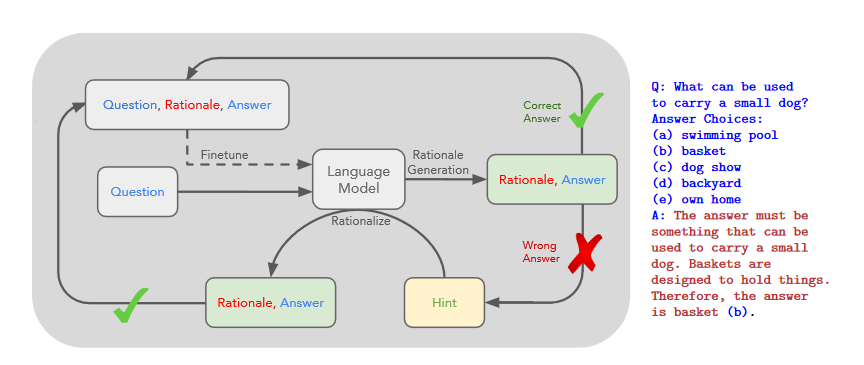
然而,上述两种思路都存在关键的局限性。对于原理增强训练和微调方法,创建大量高质量的原理是昂贵的,这比普通机器学习中使用的简单输入-输出对要复杂得多。对于Brown et al.(2020)中使用的传统的小样本提示方法,在需要推理能力的任务上效果不佳,且往往不会随着语言模型规模(Rae et al, 2021)的增加而有实质性的提升。在本文中,我们结合了这两种思想的长处,避免了它们的局限性。具体来说,给定一个由三元组〈输入,思维链,输出〉组成的提示,我们探讨语言模型对推理任务进行小样本提示的能力。思维链是导致最终输出的一系列中间自然语言推理步骤,我们将这种方式称为思维链提示。示例提示如图1所示。
我们对算术、常识和符号推理基准进行了实证评估,发现思维链提示优于标准提示,有时甚至达到惊人的程度。图2展示了这样一个结果--在数学应用题(Cobbe et al, 2021)的GSM8K测试集上,使用PaLM 540B的思维链提示大大优于标准提示,取得了新的性能。仅提示的方法很重要,因为它不需要大型的训练数据集,而且单个模型检查点可以执行许多任务而不失一般性。这项工作强调了如何通过几个关于任务( c.f.通过一个大型的训练数据集自动学习输入和输出的模式)的自然语言数据的例子来学习大型语言模型。
我们首先考虑图1形式的数学应用题,它衡量语言模型的算术推理能力。虽然对于人类来说很简单,但是算术推理是语言模型经常要面对的任务。令人惊讶的是,当与540B参数语言模型一起使用时,链式提示在多个任务上表现出与特定任务微调模型相当的性能,甚至在具有挑战性的GSM8K基准程序(Cobbe et al, 2021)上达到了新的水平。
最强烈的思维链提示结果汇总在图4中,每个模型集合、模型大小和基准的所有实验输出如附录中表2所示。有三个关键的点。首先,图4表明,思维链提示是模型尺度( Wei et al , 2022b)的一种涌现能力。也就是说,对于较小的模型,思维链提示并不会对性能产生积极影响,只有在使用了~100B参数的模型时才会产生性能增益。我们定性地发现,较小规模的模型产生了流畅但不合逻辑的思维链,导致了比标准提示更低的性能。
]]><h1>思维链提示在大型语言模型中引发推理</h1>
<h2 id="摘要">摘要</h2>
<p>我们探索了如何生成一个思想链--一系列中间推理步骤--显著提高大型语言模型执行复杂推理的能力。特别地,我们展示了这种推理能力是如何在足够大的语言模型中通过一种简单的方法--思维链提Reflexion: Language Agents with Verbal Reinforcement Learninghttps://www.aweisite.top/posts/dd4362ac.html2023-11-24T10:40:00.000Z2026-06-11T09:31:37.278Z反射:言语强化学习的语言代理
大型语言模型( Large Language Models,LLMs )作为目标驱动的智能体被越来越多地用于与外部环境(例如,游戏、编译器、API等)进行交互。然而,由于传统的强化学习方法需要大量的训练样本和昂贵的模型微调,这些语言智能体快速有效地从试错中学习仍然具有挑战性。我们提出了一种新的框架Reflex,它不是通过更新权重来加强语言代理,而是通过语言反馈来加强语言代理。具体来说,反应主体会对任务反馈信号进行言语反思,然后在情景记忆缓冲器中保持自己的反射性文本,以便在随后的试次中诱发更好的决策。反射足够灵活,可以包括各种类型(标量值或自由形式的语言)
]]><h1>反射:言语强化学习的语言代理</h1>
<p>原论文:<a href="http://arxiv.org/abs/2303.11366">Reflexion: Language Agents with Verbal Reinforcement Learning</a></Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyondhttps://www.aweisite.top/posts/7417c6fb.html2023-11-23T19:51:00.000Z2026-06-11T09:31:37.278Z在实践中利用LLMs的能力:对Chatgpt和更大范围的调研
本文为从事大型语言模型( Large Language Models,LLMs )工作的从业者和最终用户在其下游自然语言处理( Natural Language Processing,NLP )任务中提供了一个全面而实用的指南。我们从模型、数据和下游任务的角度对LLMs的使用提供了讨论和见解。首先,我们对现有的GPT型和BERT型LLM进行了简单的介绍和总结。然后,我们讨论了预训练数据、训练数据和测试数据的影响。最重要的是,我们对各种自然语言处理任务的大型语言模型的使用和非使用情况进行了详细的讨论,例如知识密集型任务、传统的自然语言理解任务、自然语言生成任务、突现能力和注意事项
]]><h1>在实践中利用LLMs的能力:对Chatgpt和更大范围的调研</h1>
<p>原论文:<a href="http://arxiv.org/abs/2304.13712"><em>Harnessing the Power of LLMs in Practice: A Surac平台在Jupyter Notebook中使用自定义conda环境https://www.aweisite.top/posts/12ede4e.html2023-10-22T17:38:00.000Z2026-06-11T09:31:37.282Z基本步骤

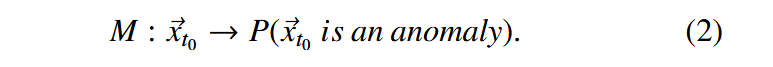
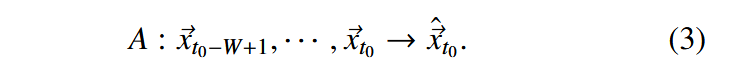

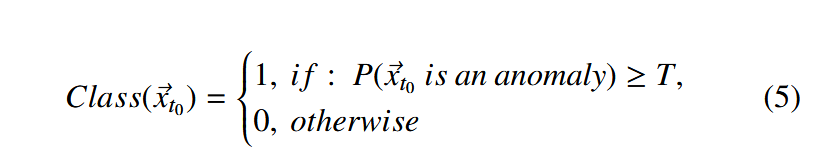

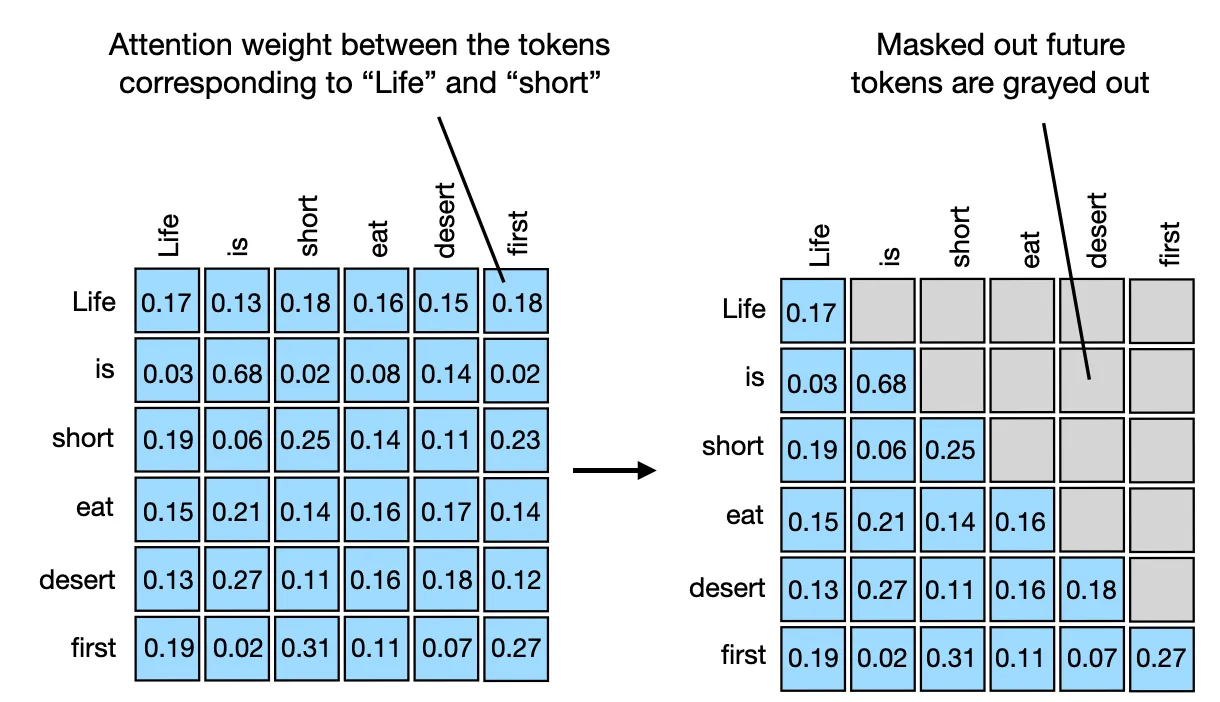 Attention在经过Mask后,只有一部分被保留。也就是下面右图中的左上部分。
Attention在经过Mask后,只有一部分被保留。也就是下面右图中的左上部分。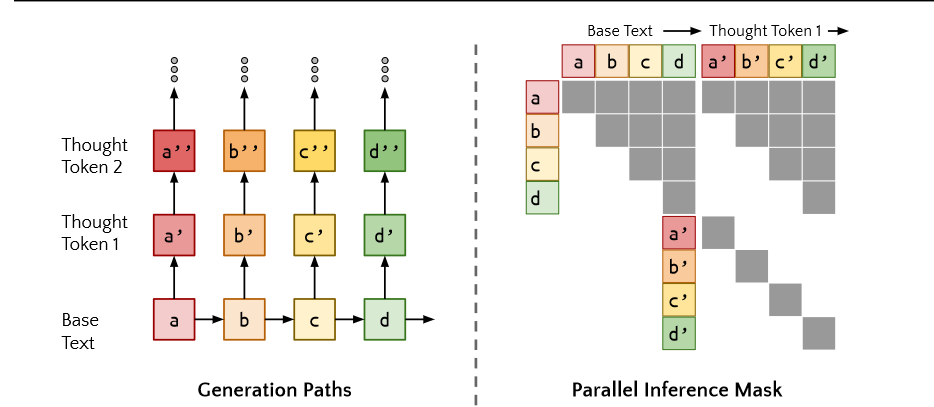



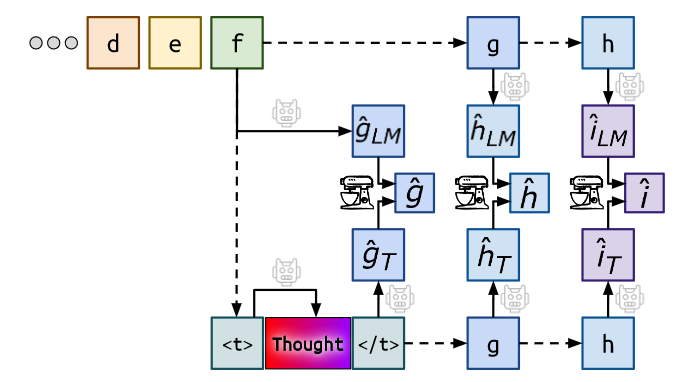 其中实线表示语言模型计算,虚线表示通过Teacher-forcing插入token,搅拌器表示混合头。
其中实线表示语言模型计算,虚线表示通过Teacher-forcing插入token,搅拌器表示混合头。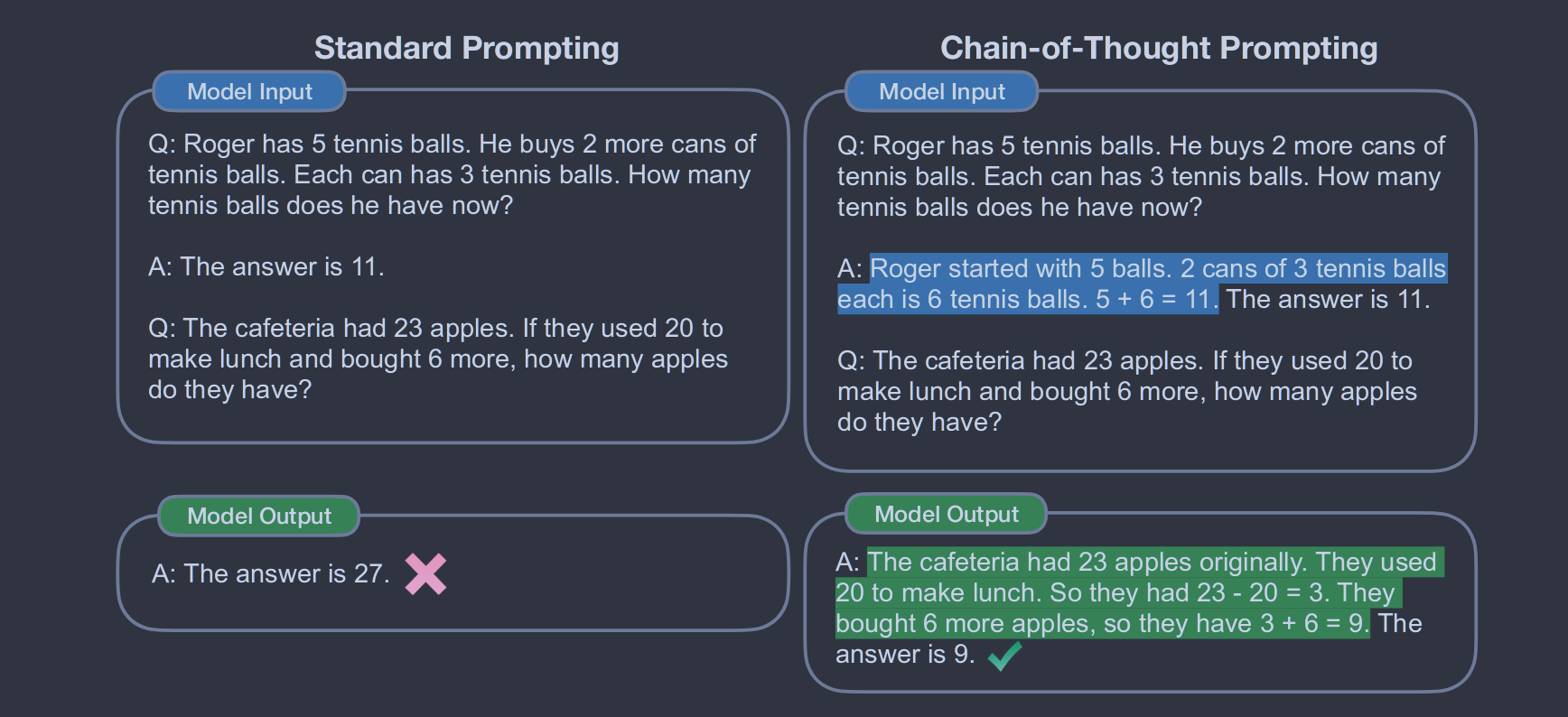
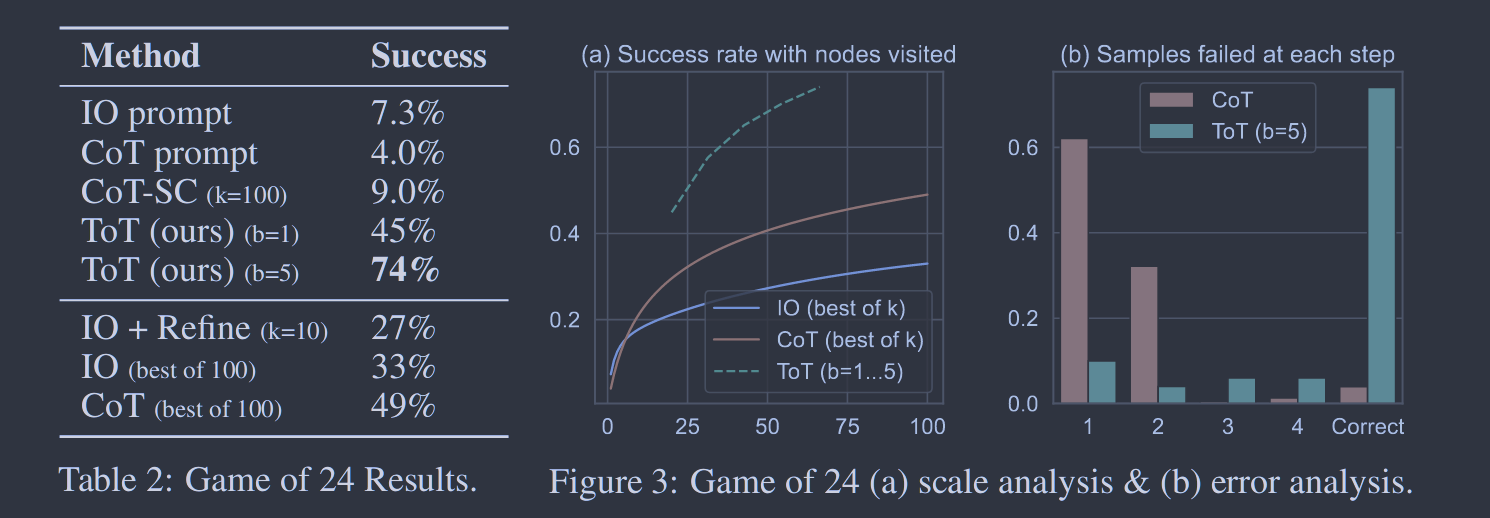
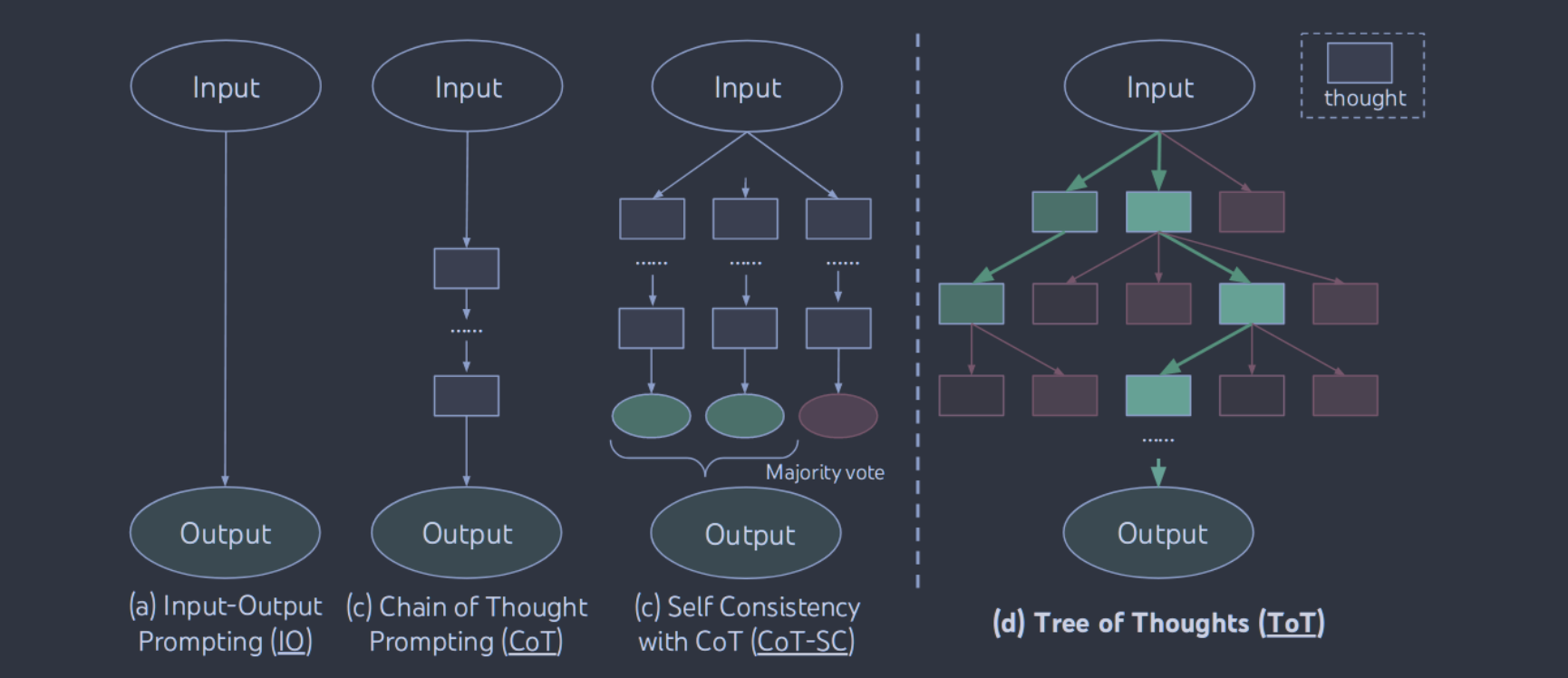
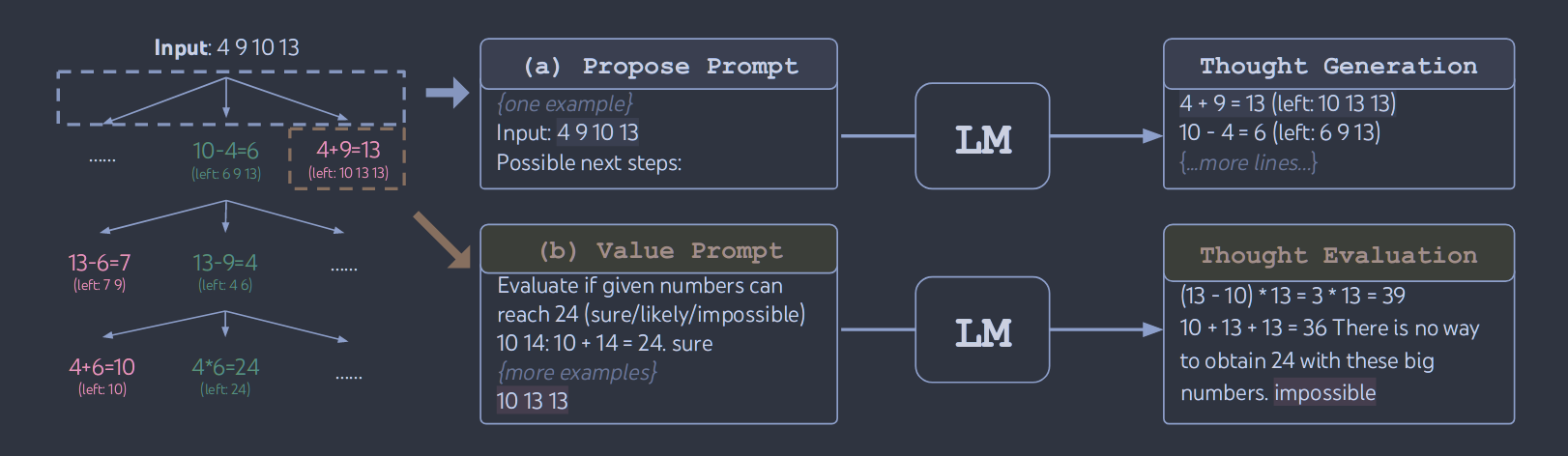
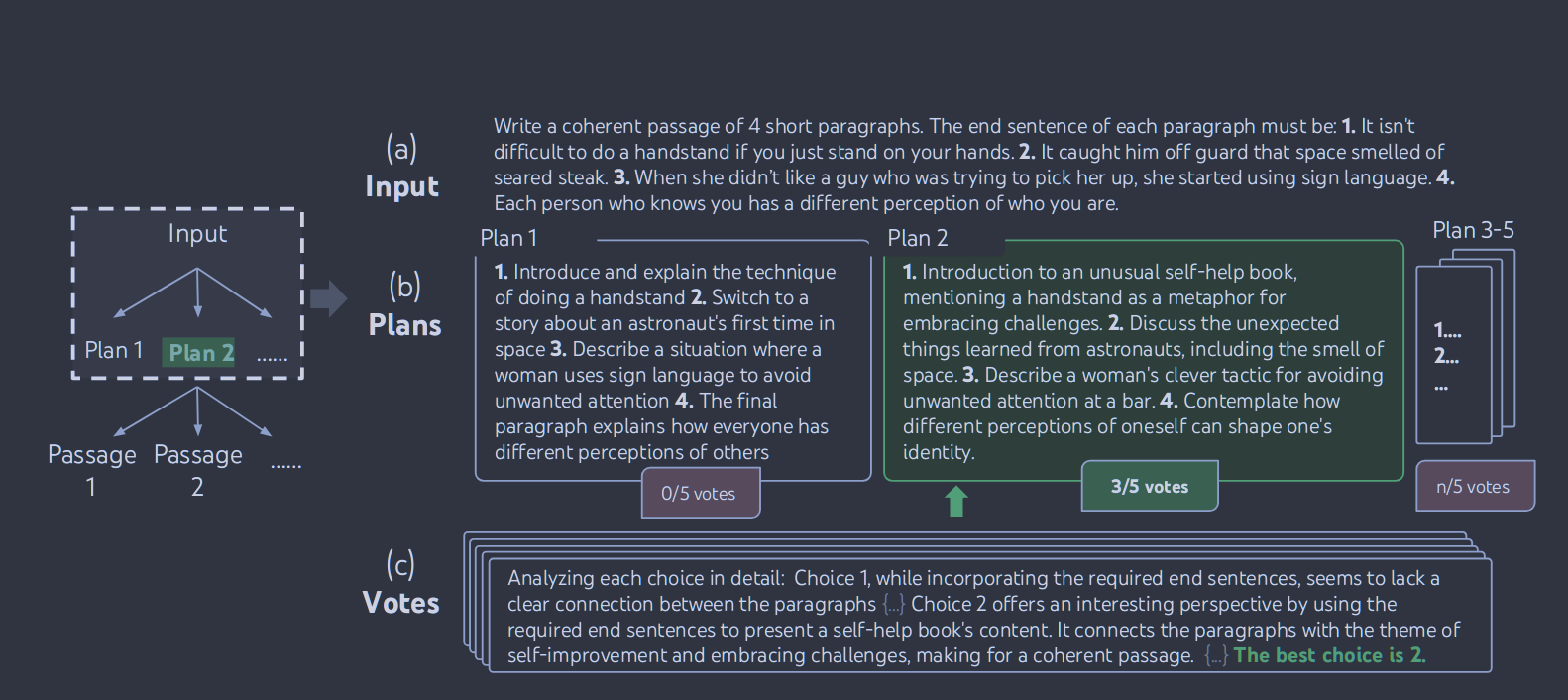
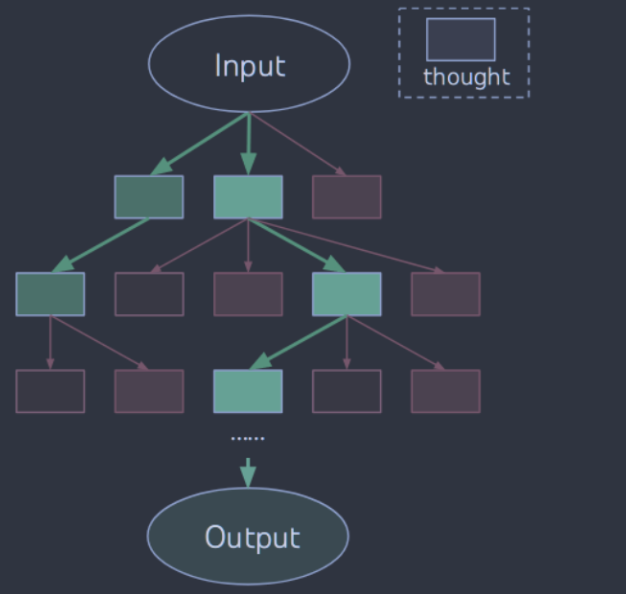
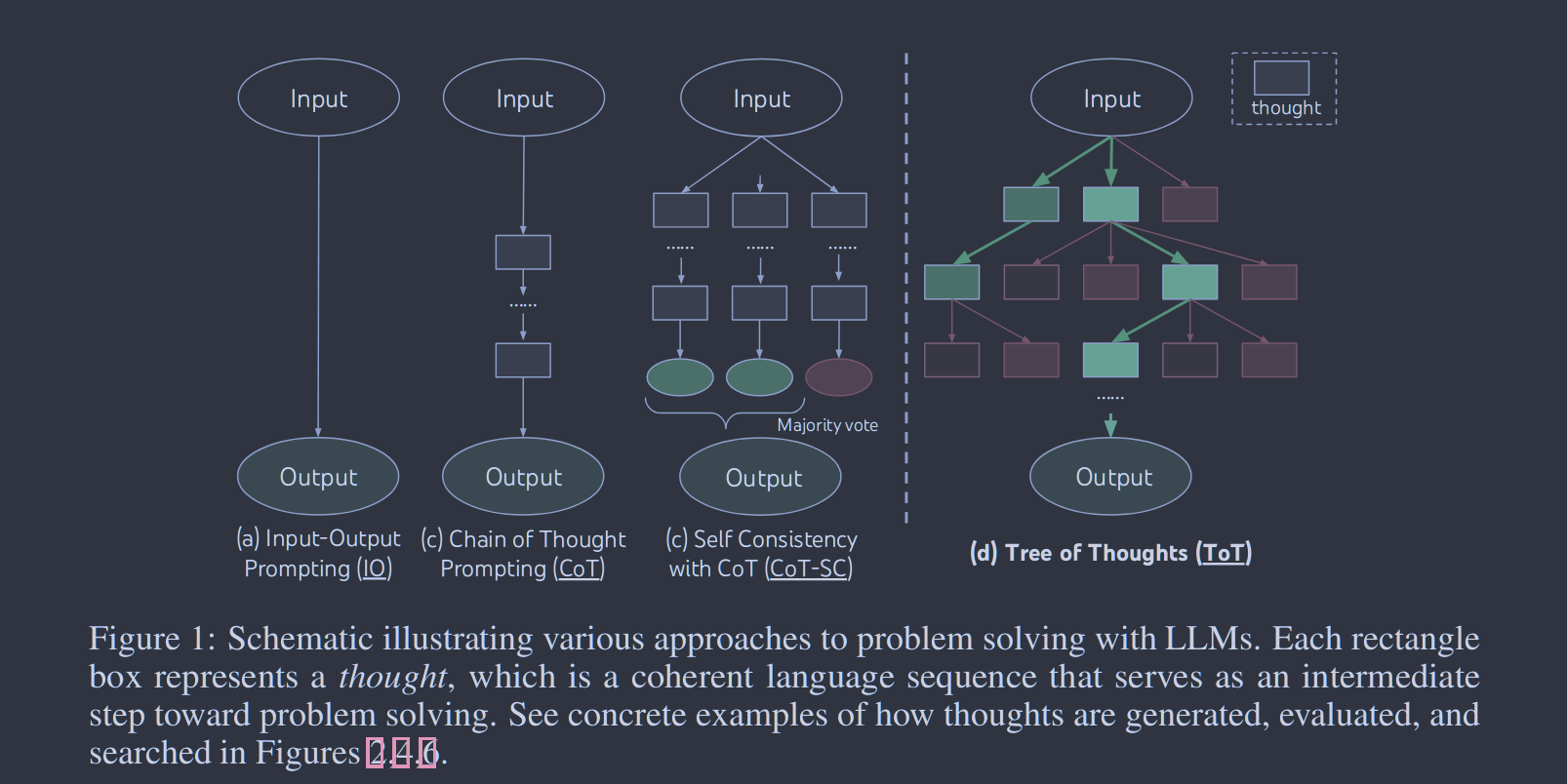 图1:图示说明了用LLMs解决问题的各种方法。每个矩形框代表一种思想,它是一个连贯的语言序列,是问题解决的中间步骤。在图2、4、6中可以看到思想是如何产生、评价和搜索的具体例子。
图1:图示说明了用LLMs解决问题的各种方法。每个矩形框代表一种思想,它是一个连贯的语言序列,是问题解决的中间步骤。在图2、4、6中可以看到思想是如何产生、评价和搜索的具体例子。



 (2)
(2)
 (3)
(3)
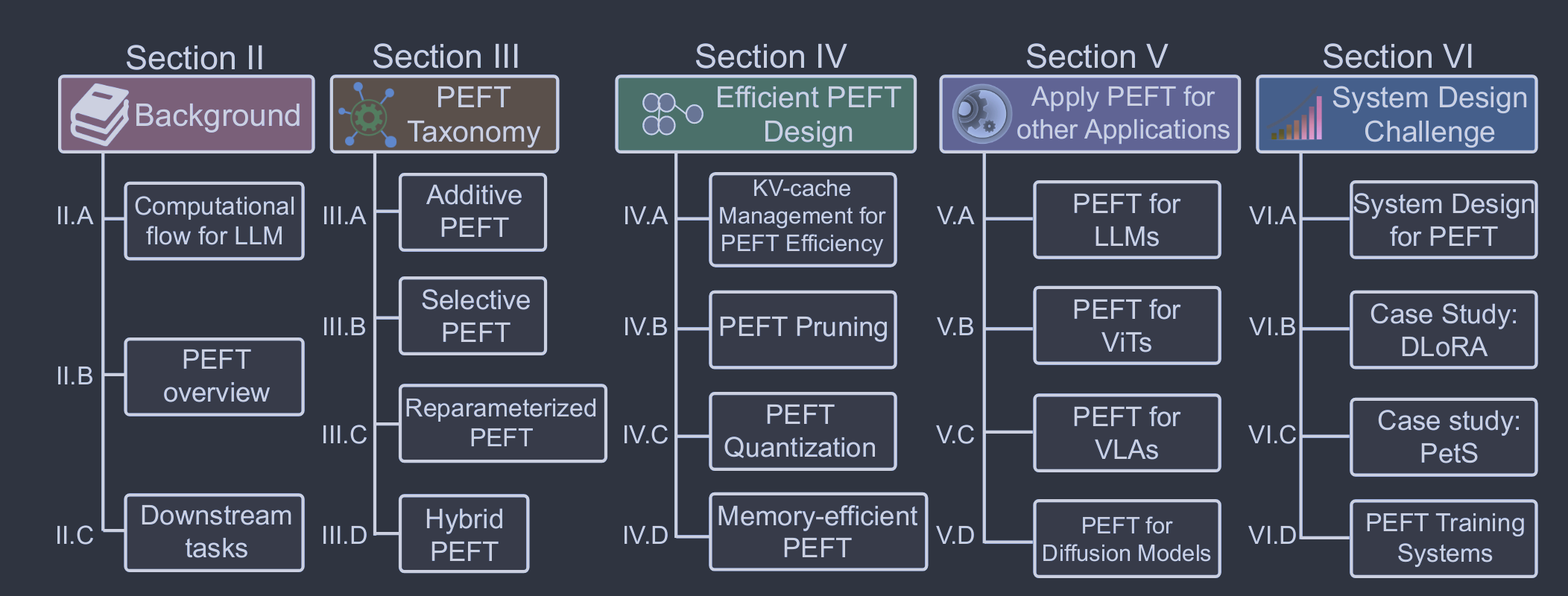
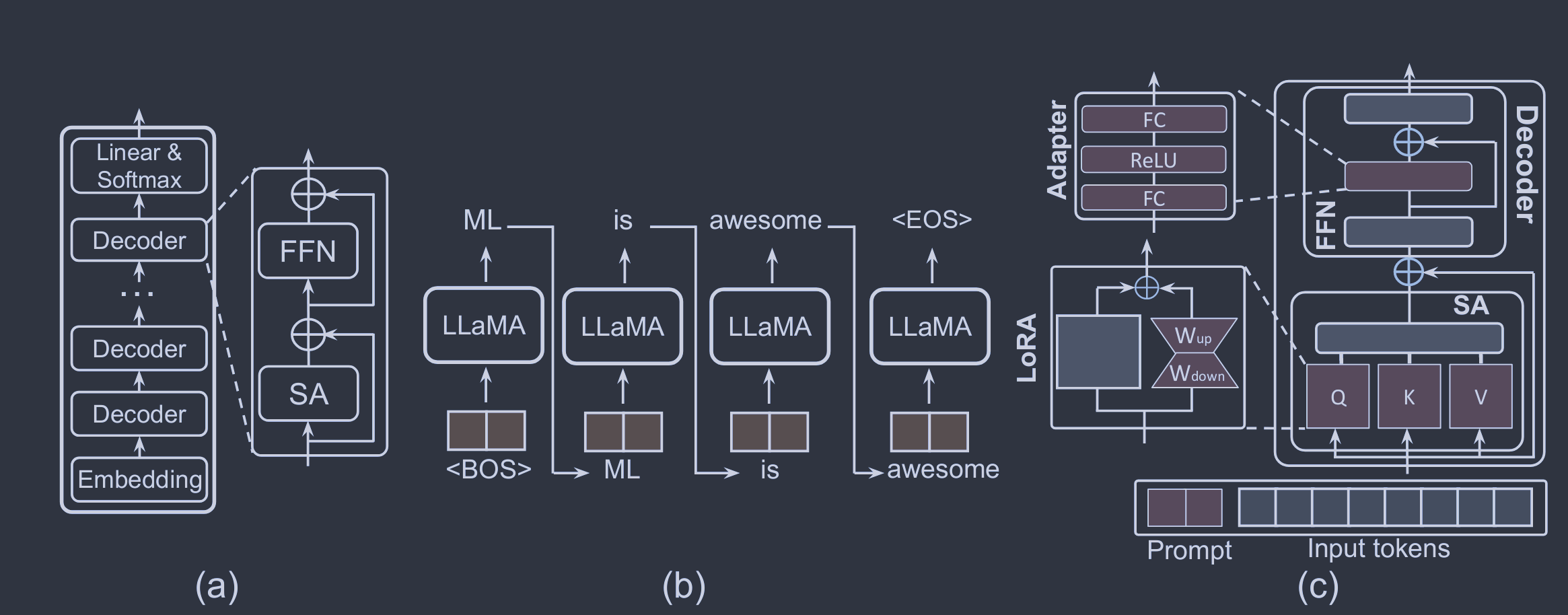


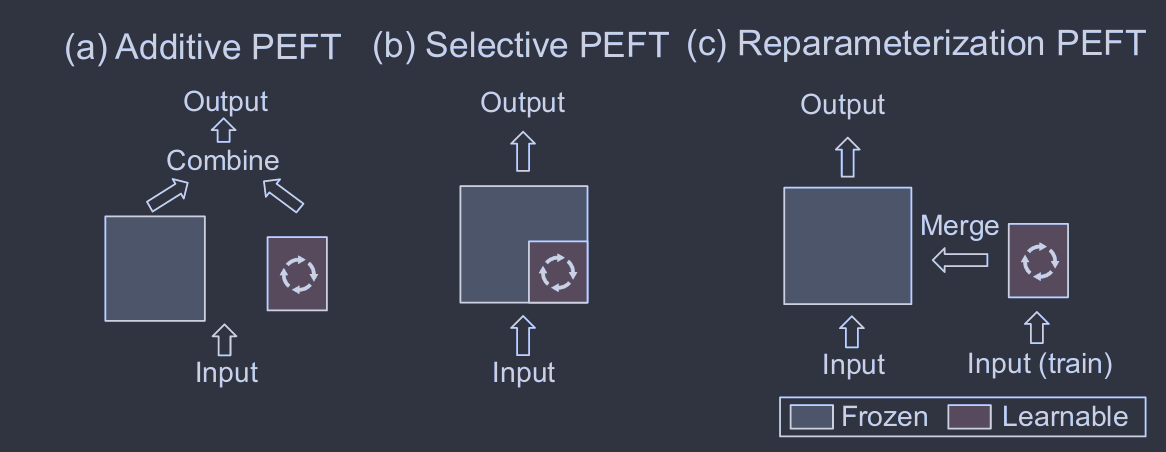
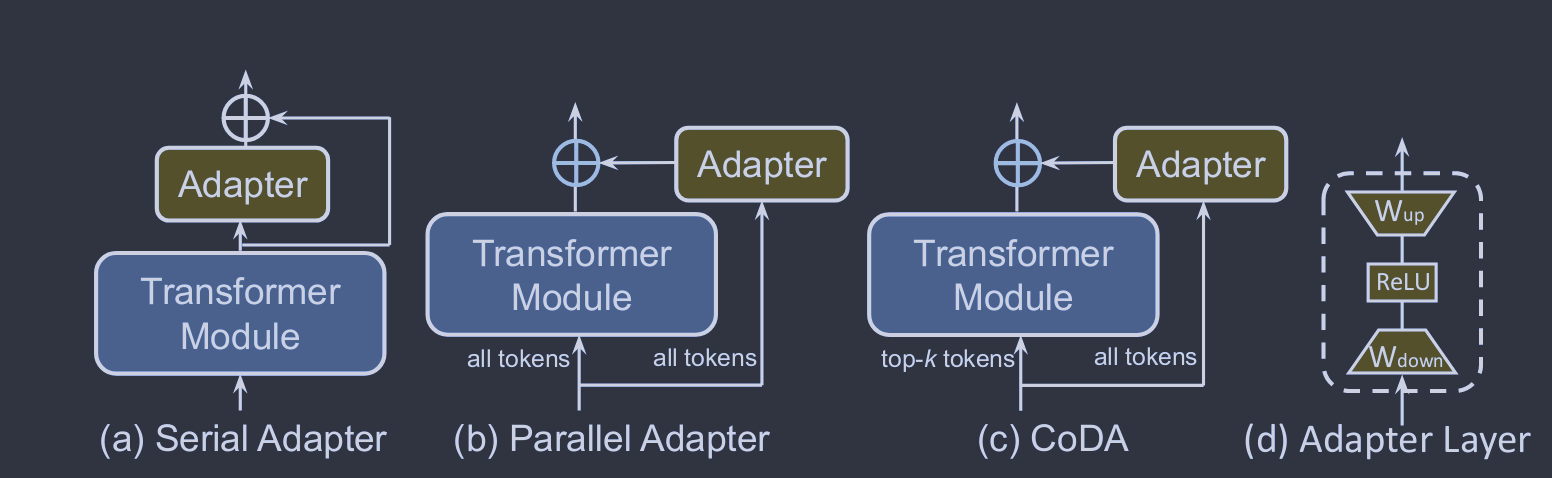
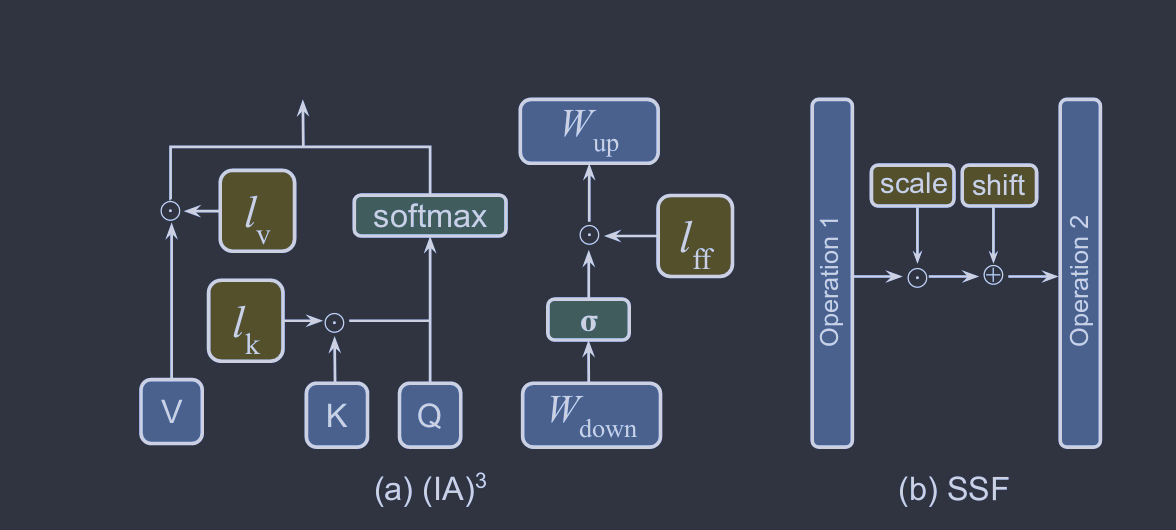
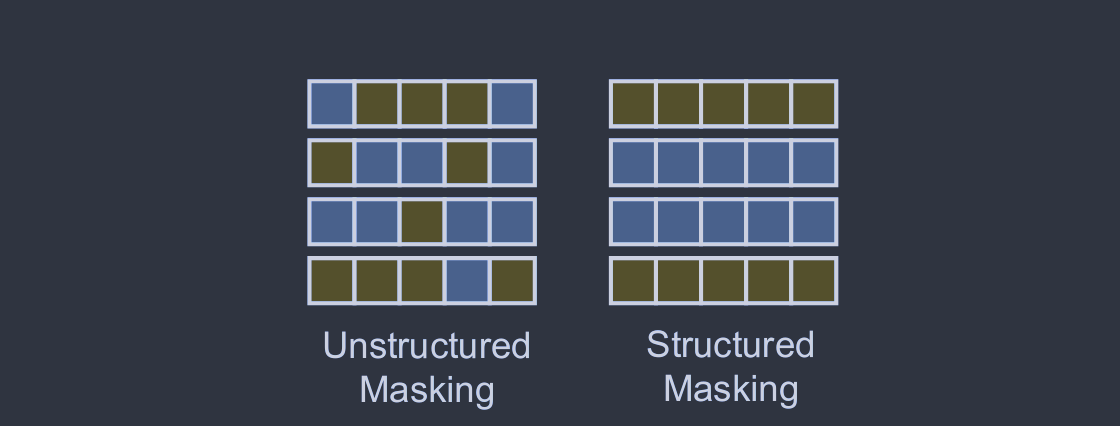
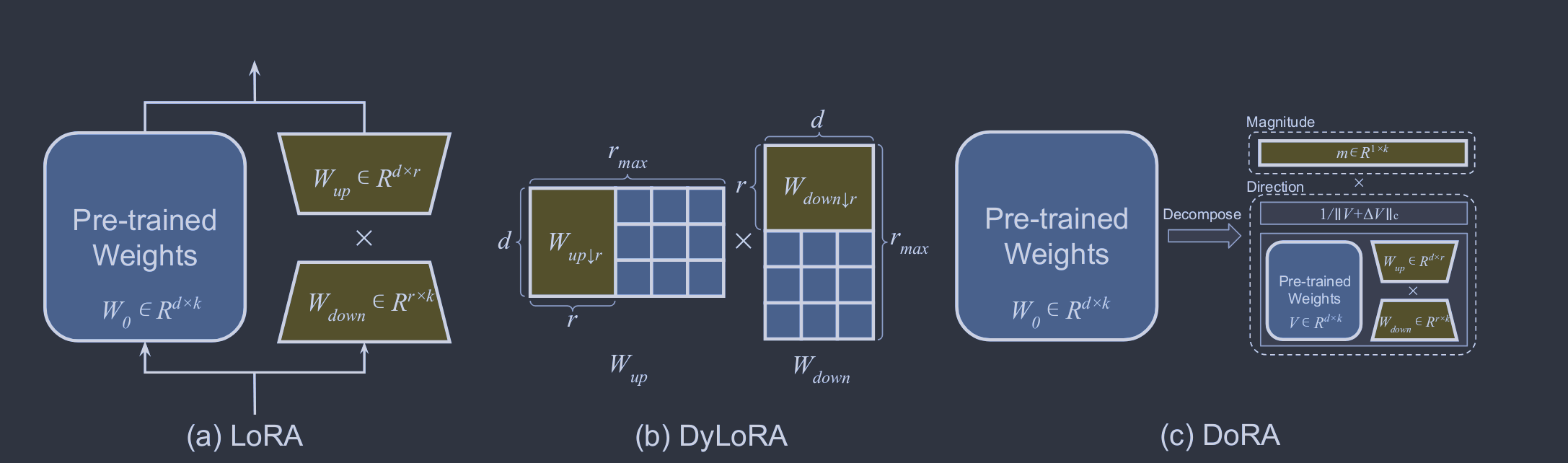
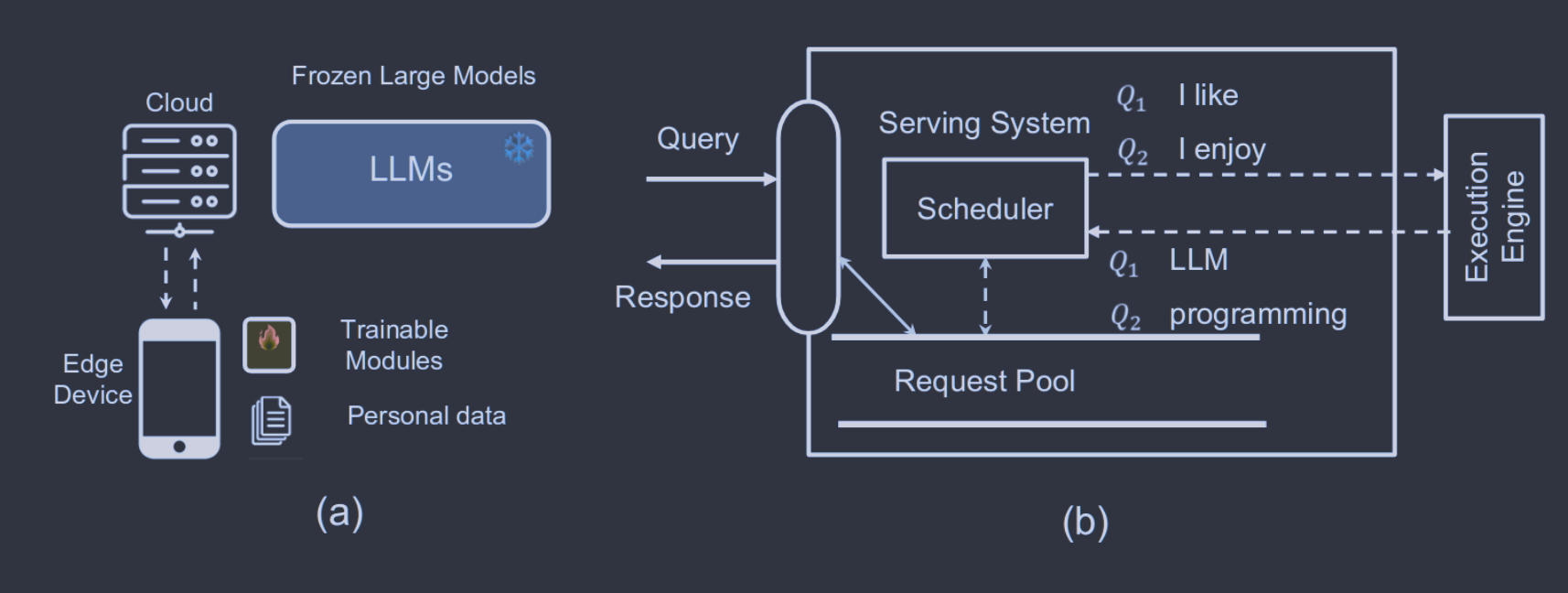

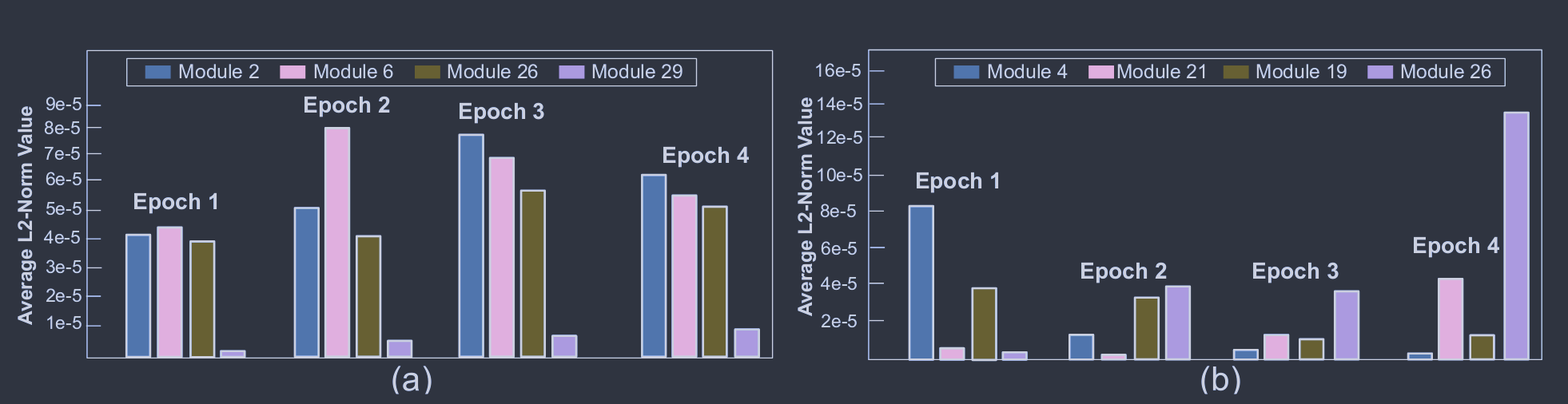
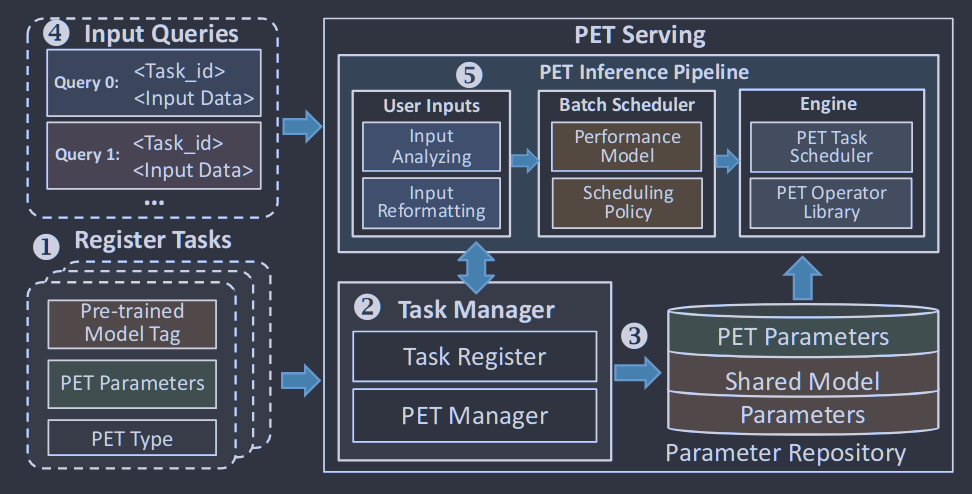
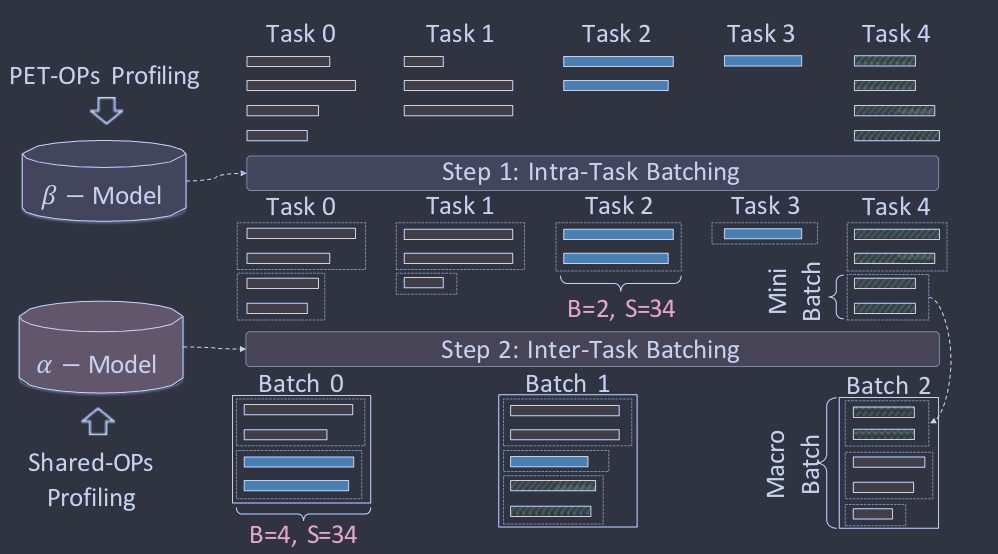
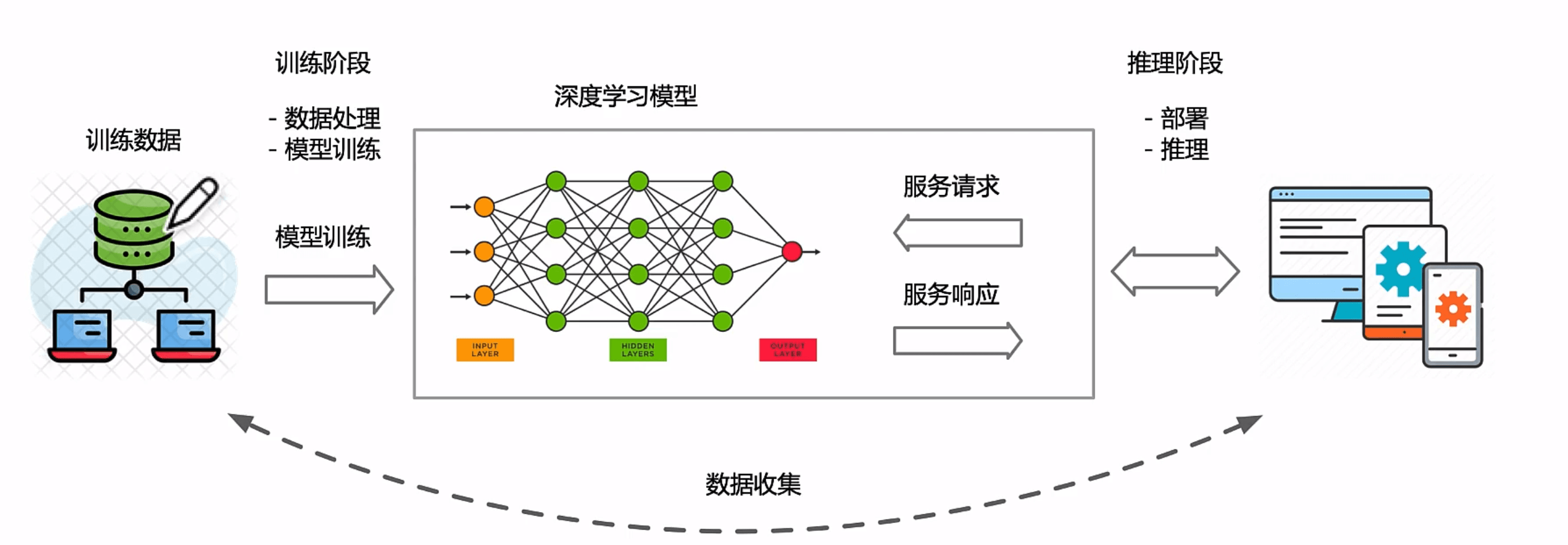
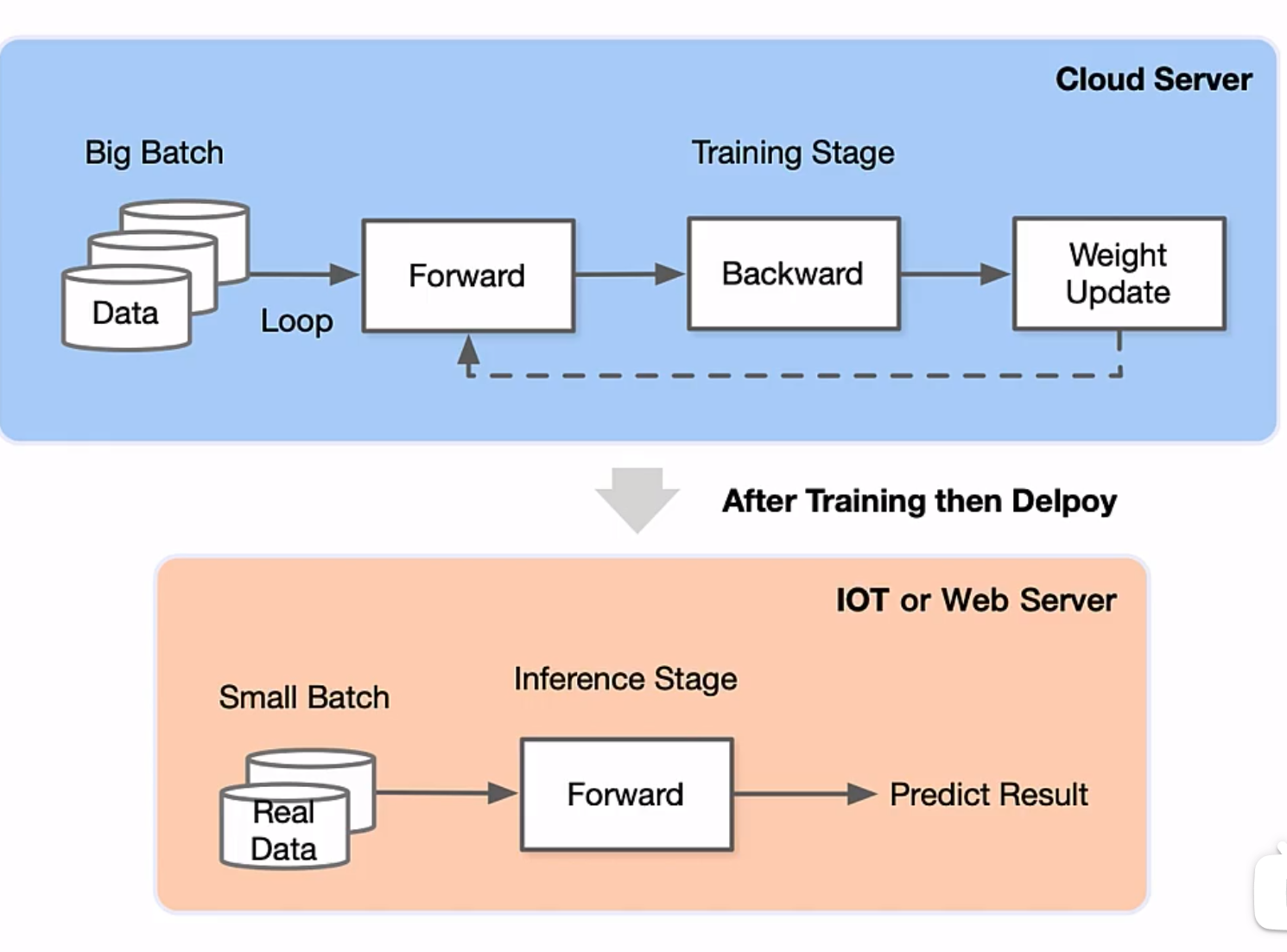
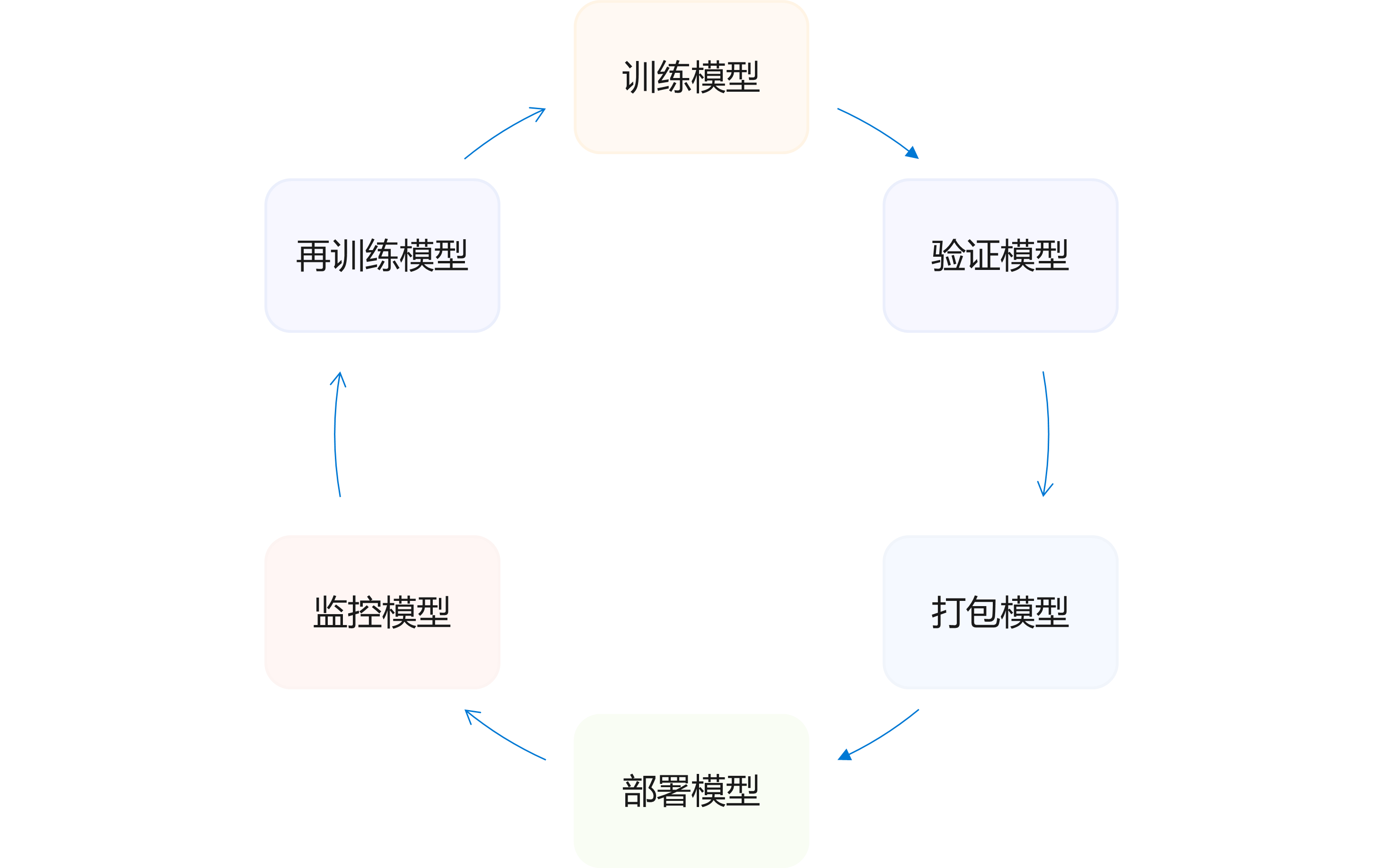
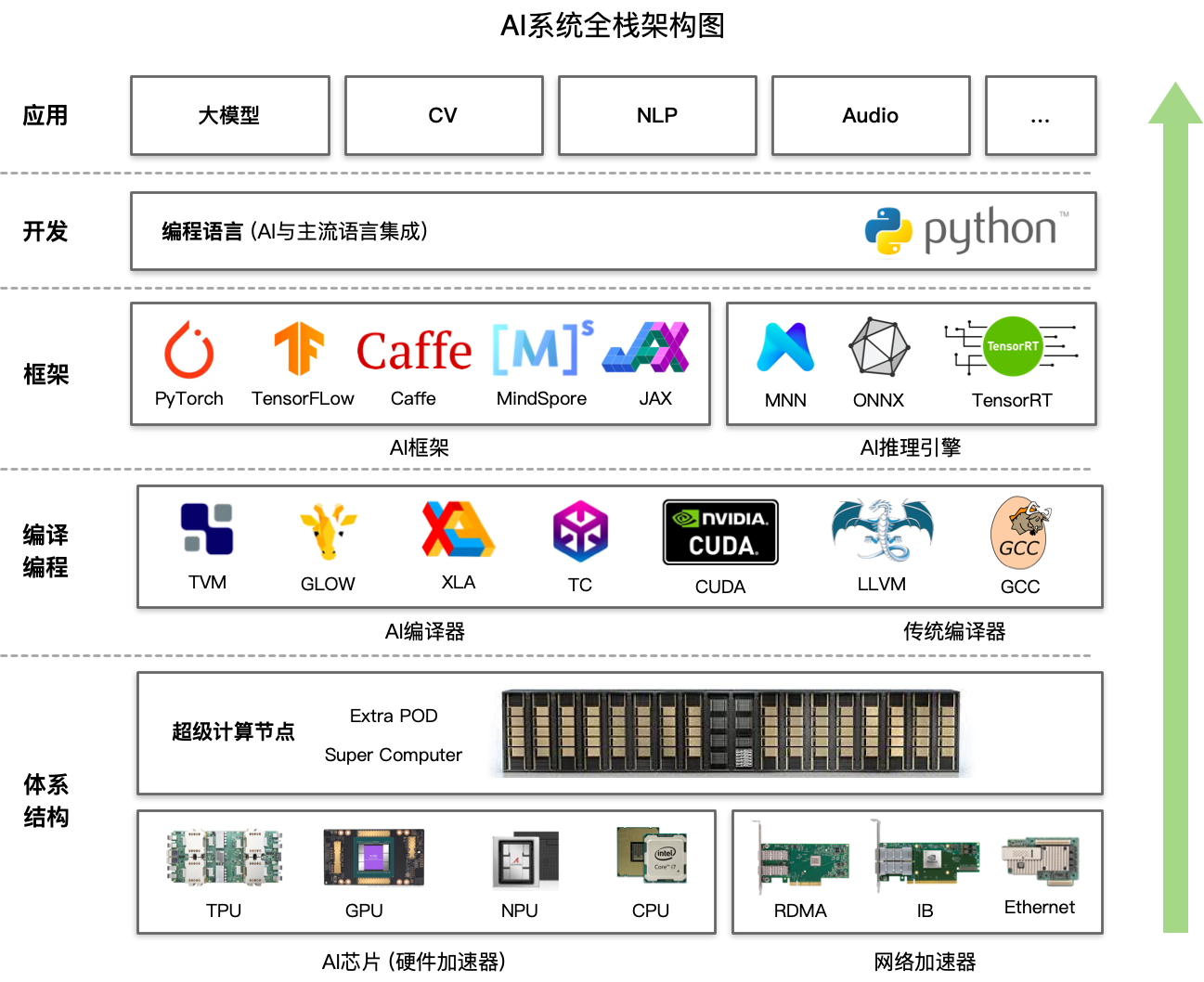

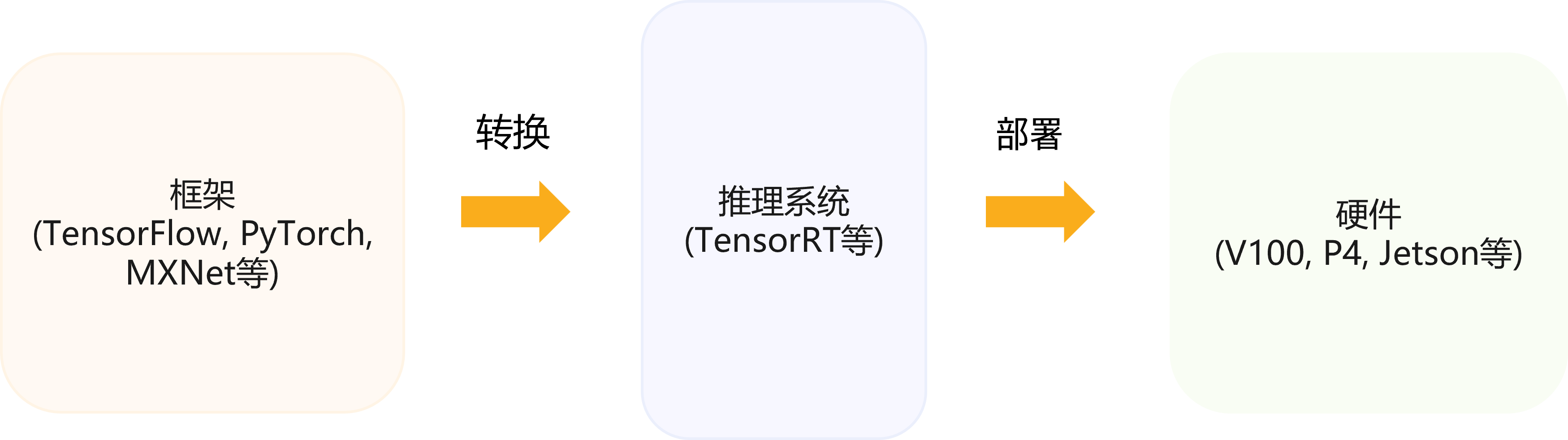
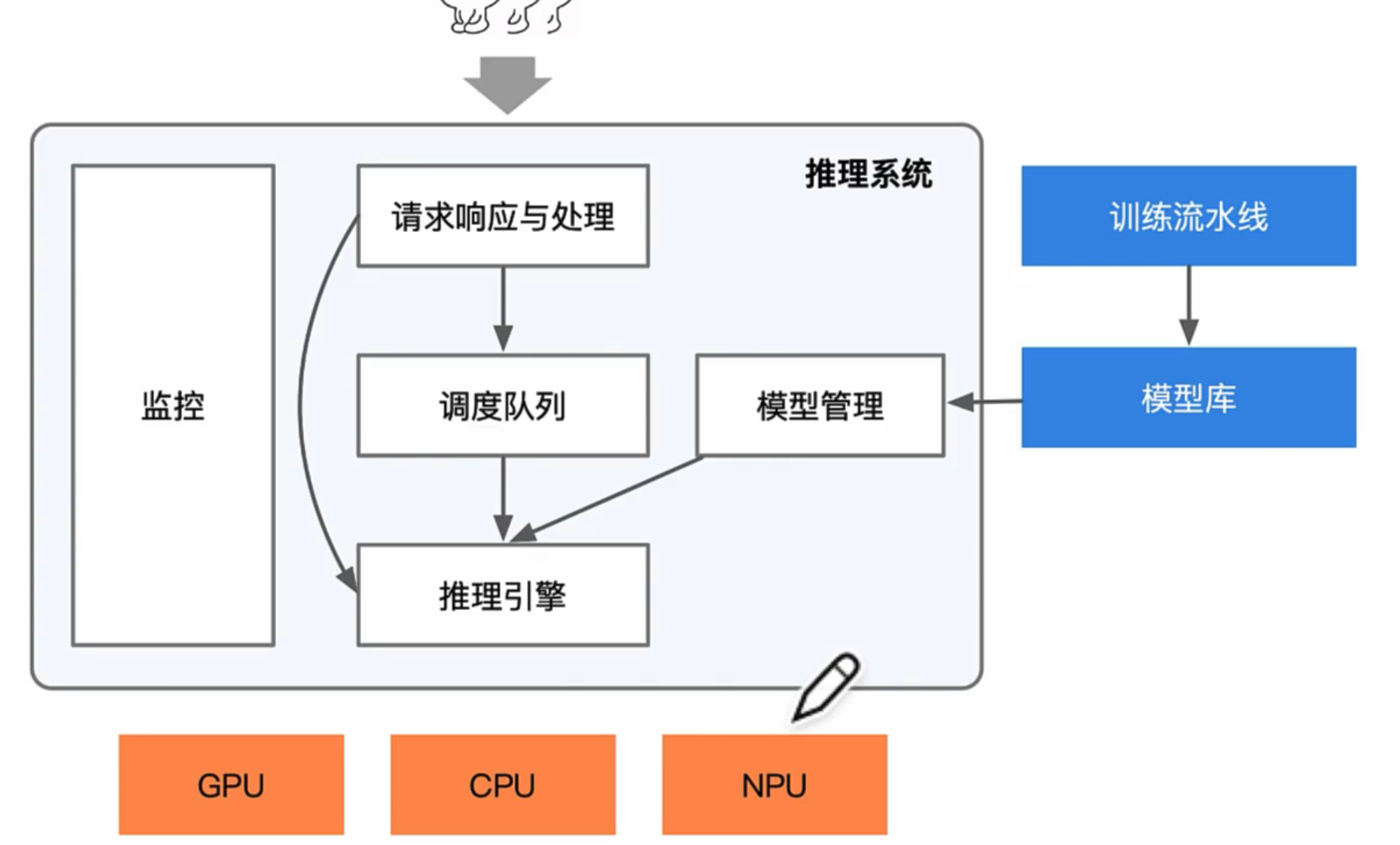
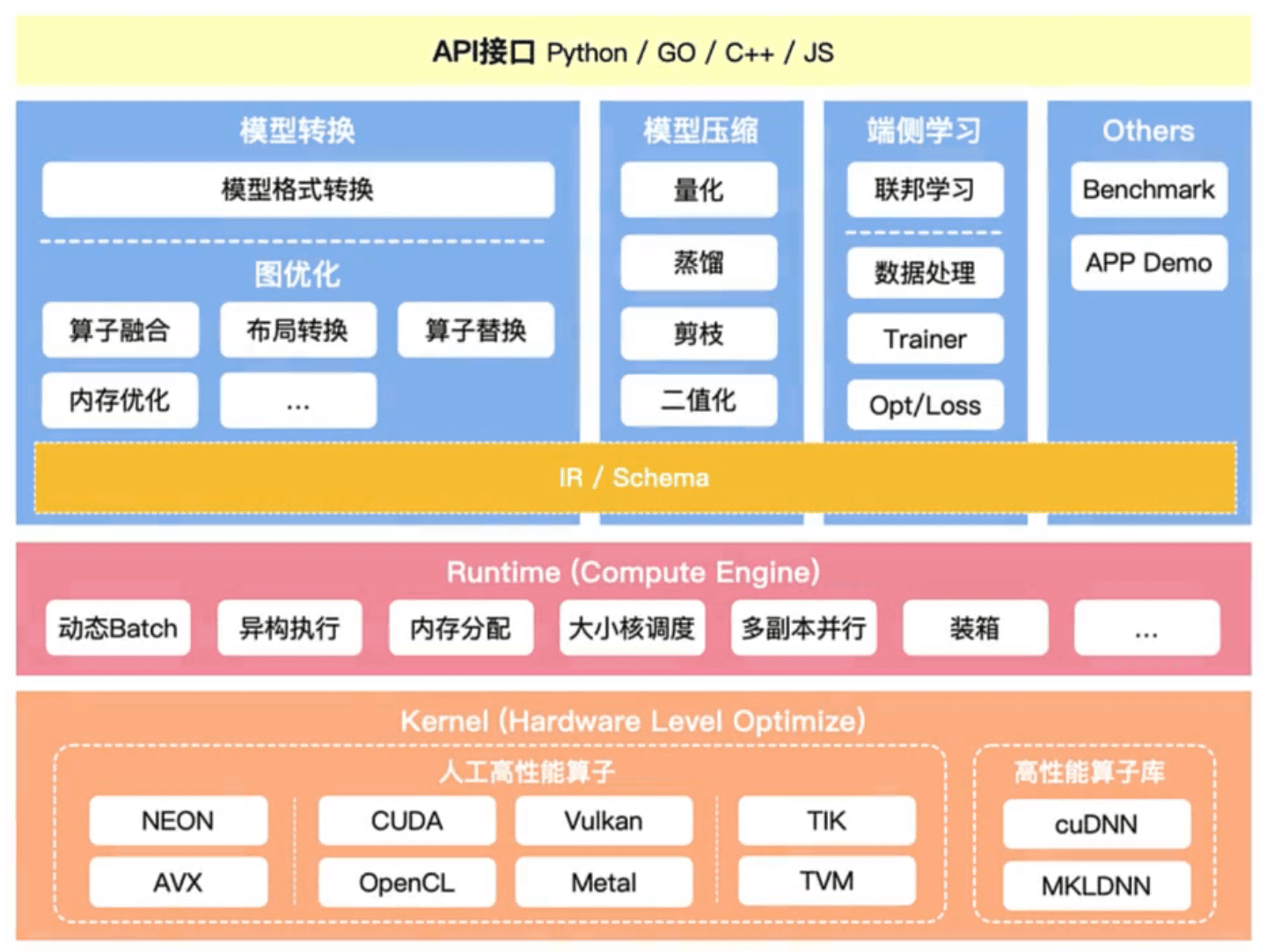
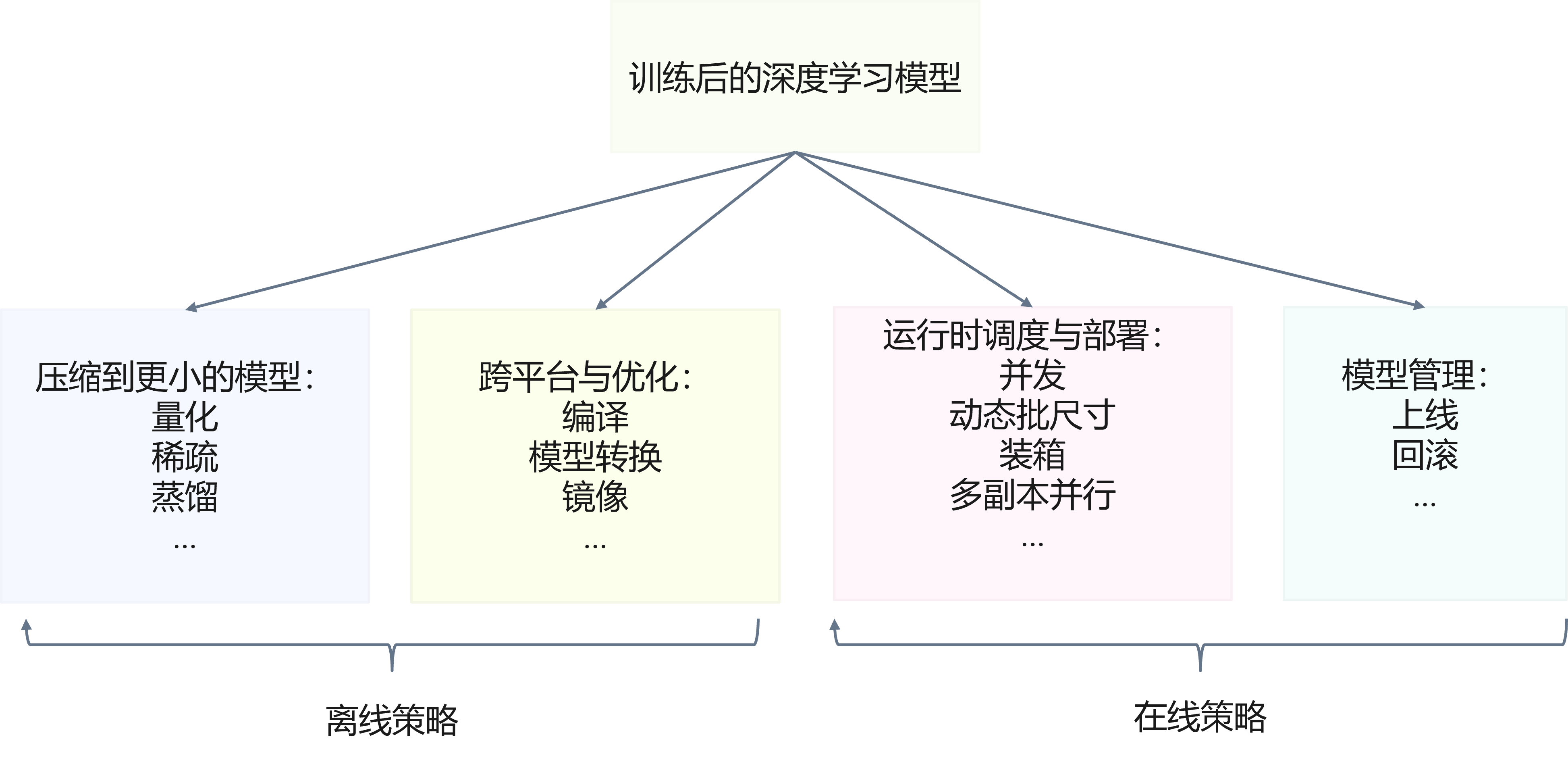
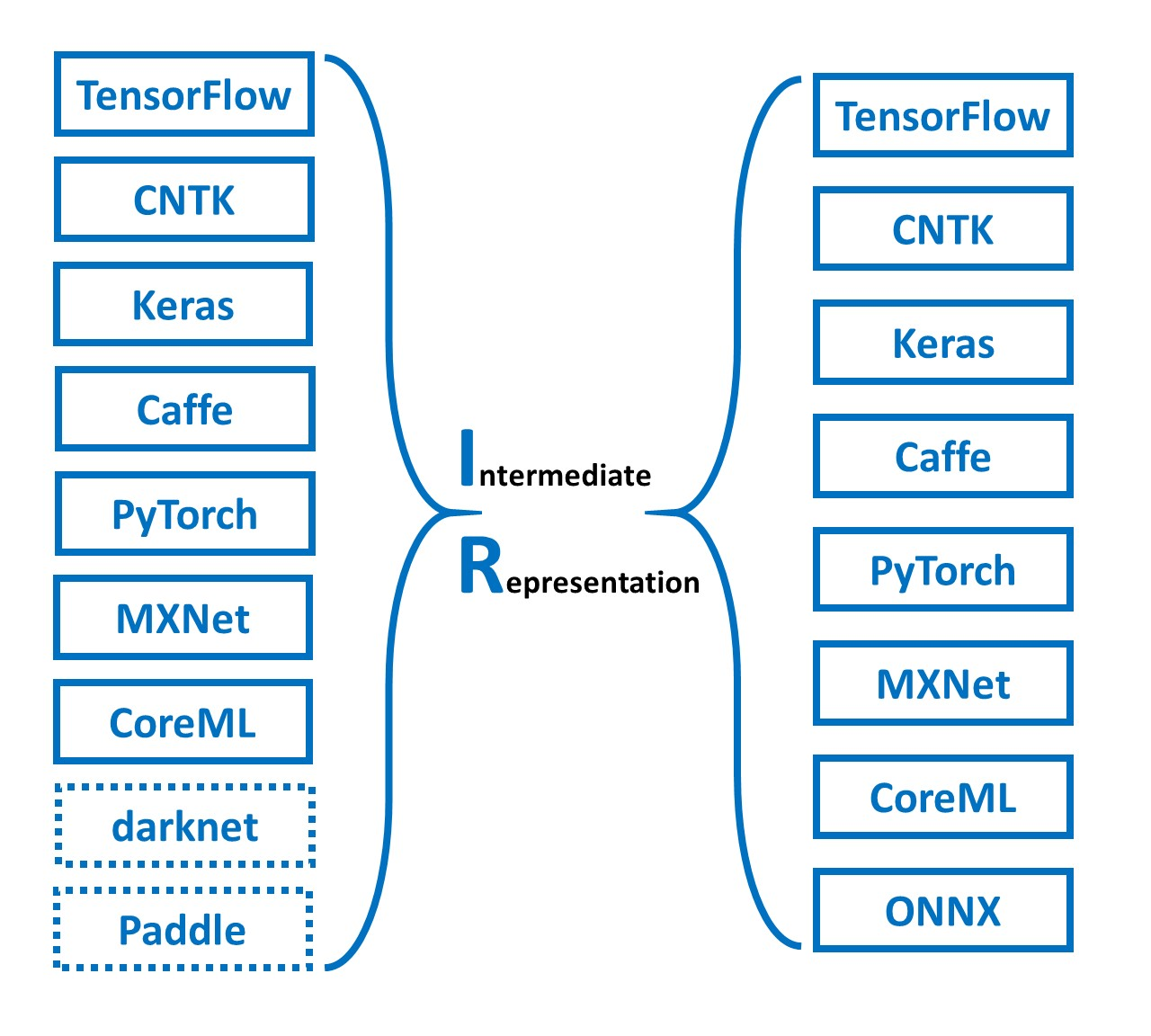
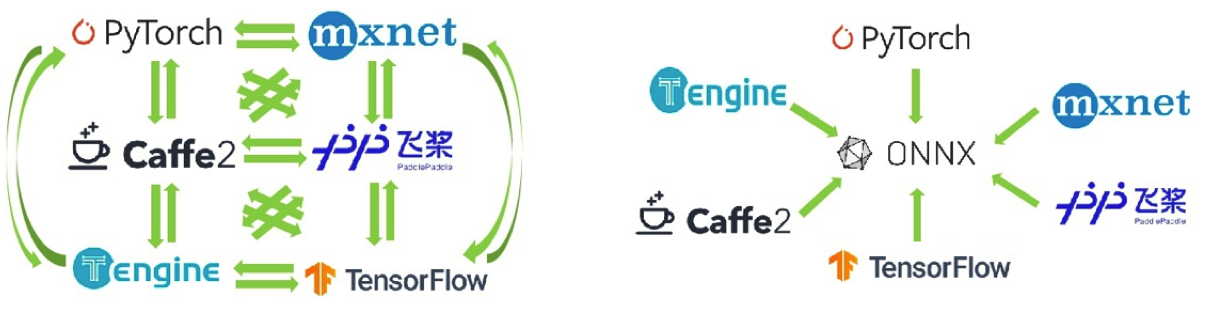
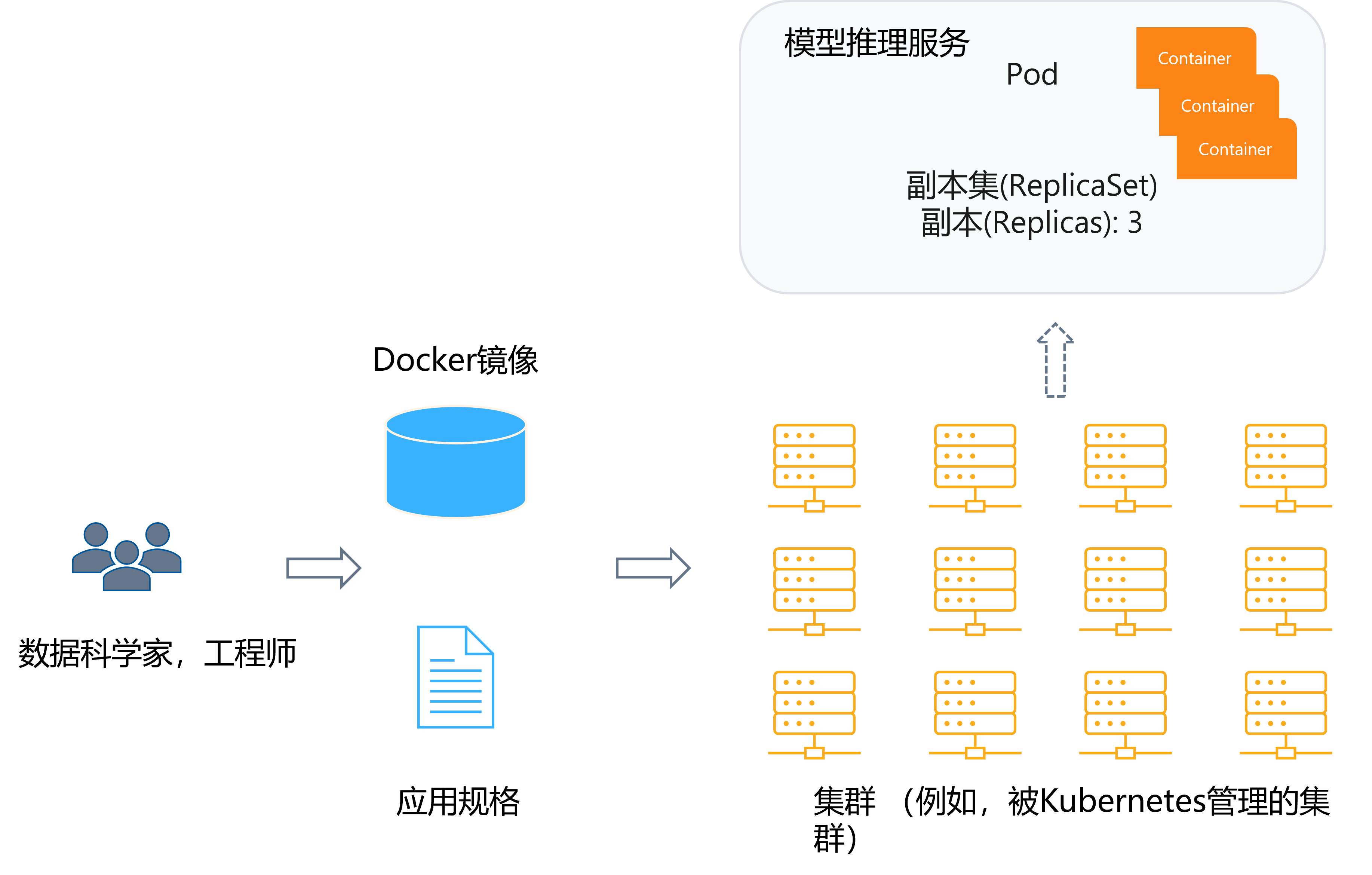
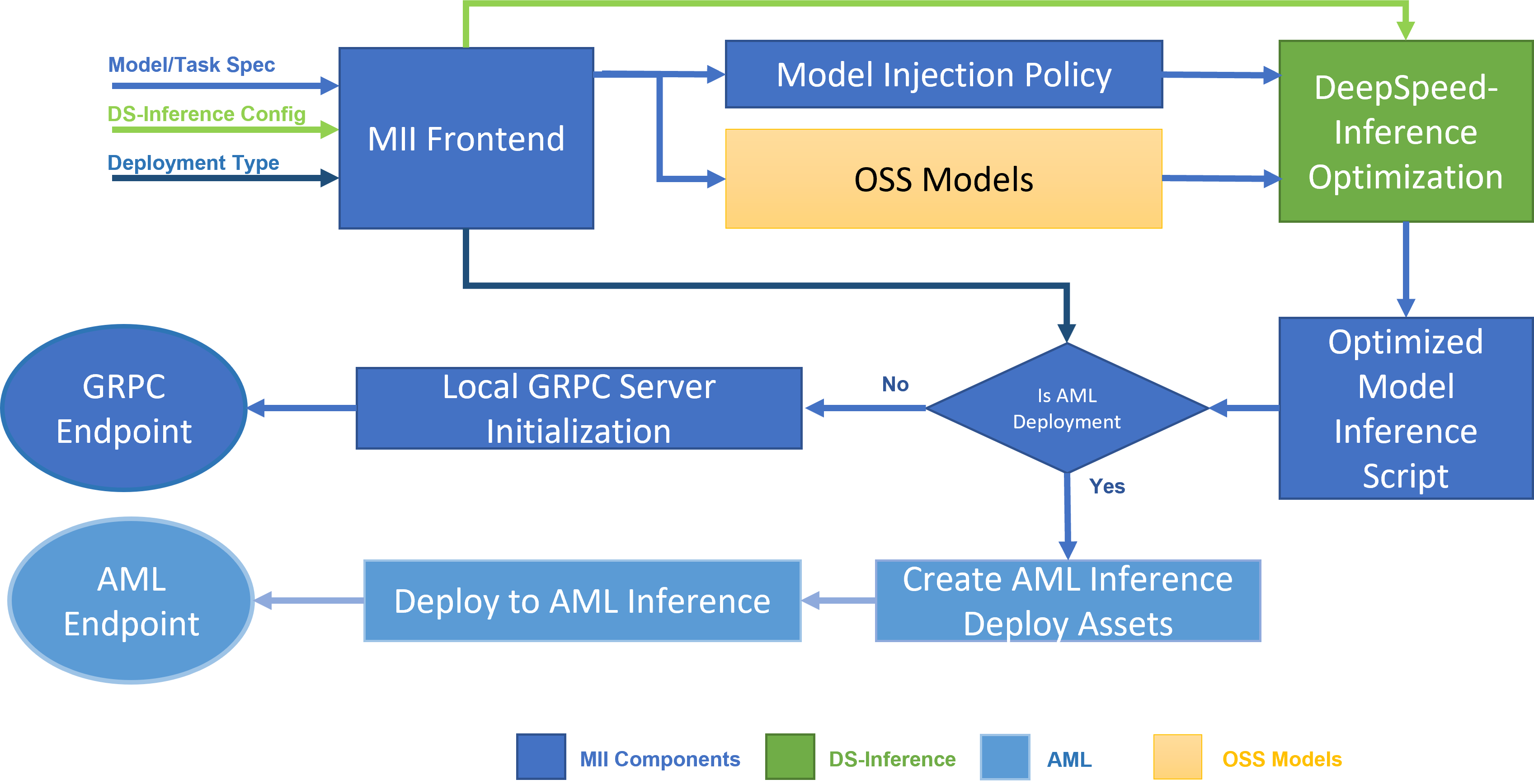
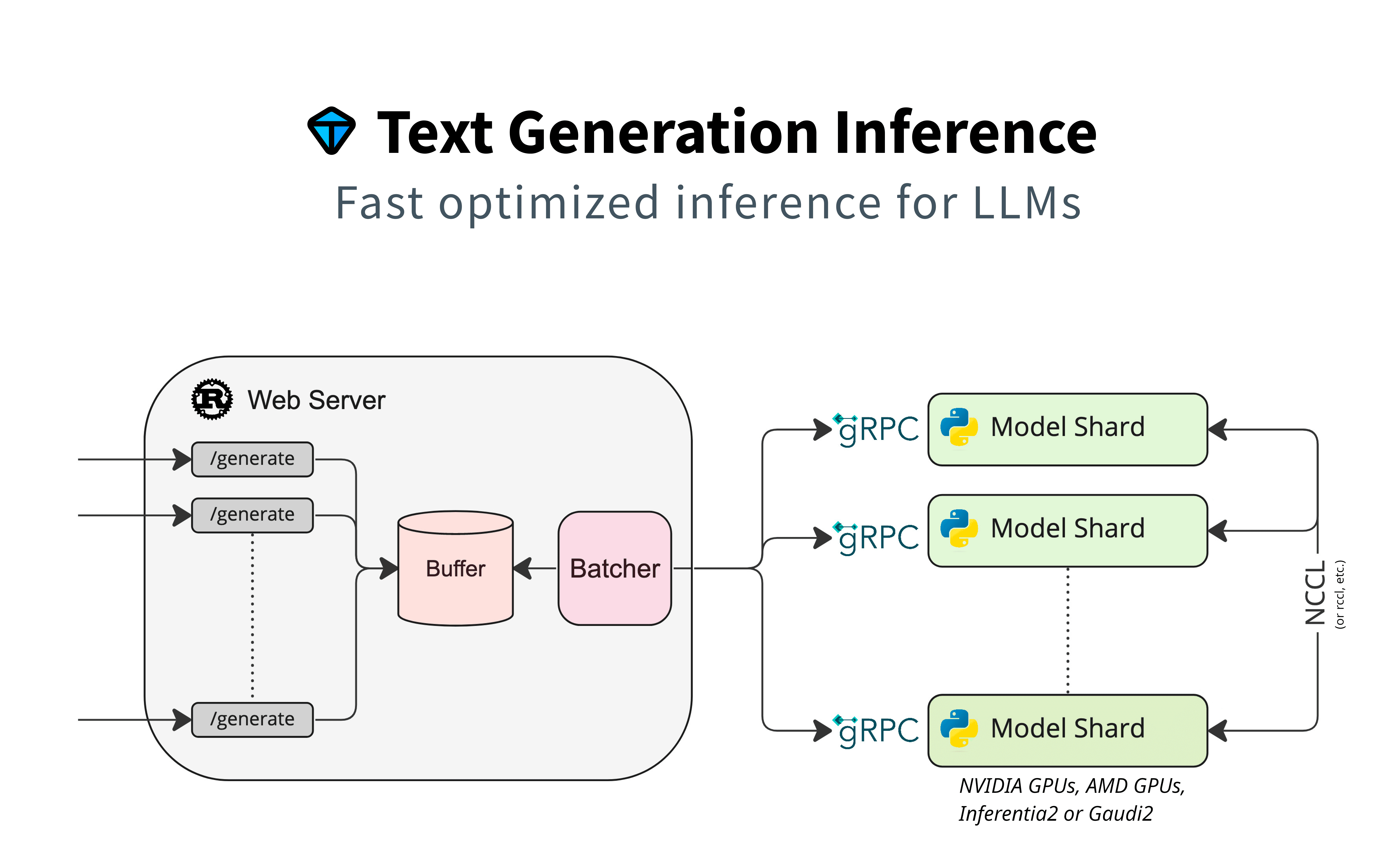
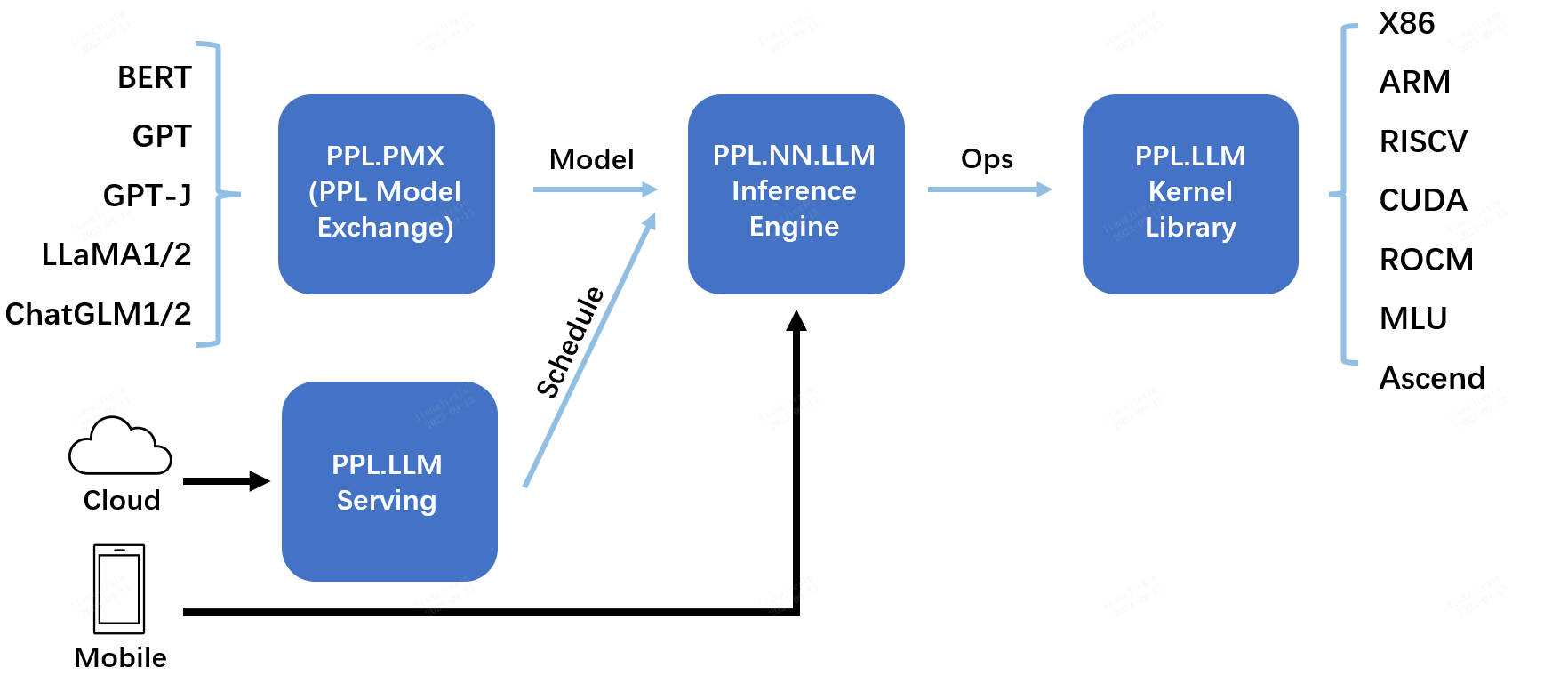
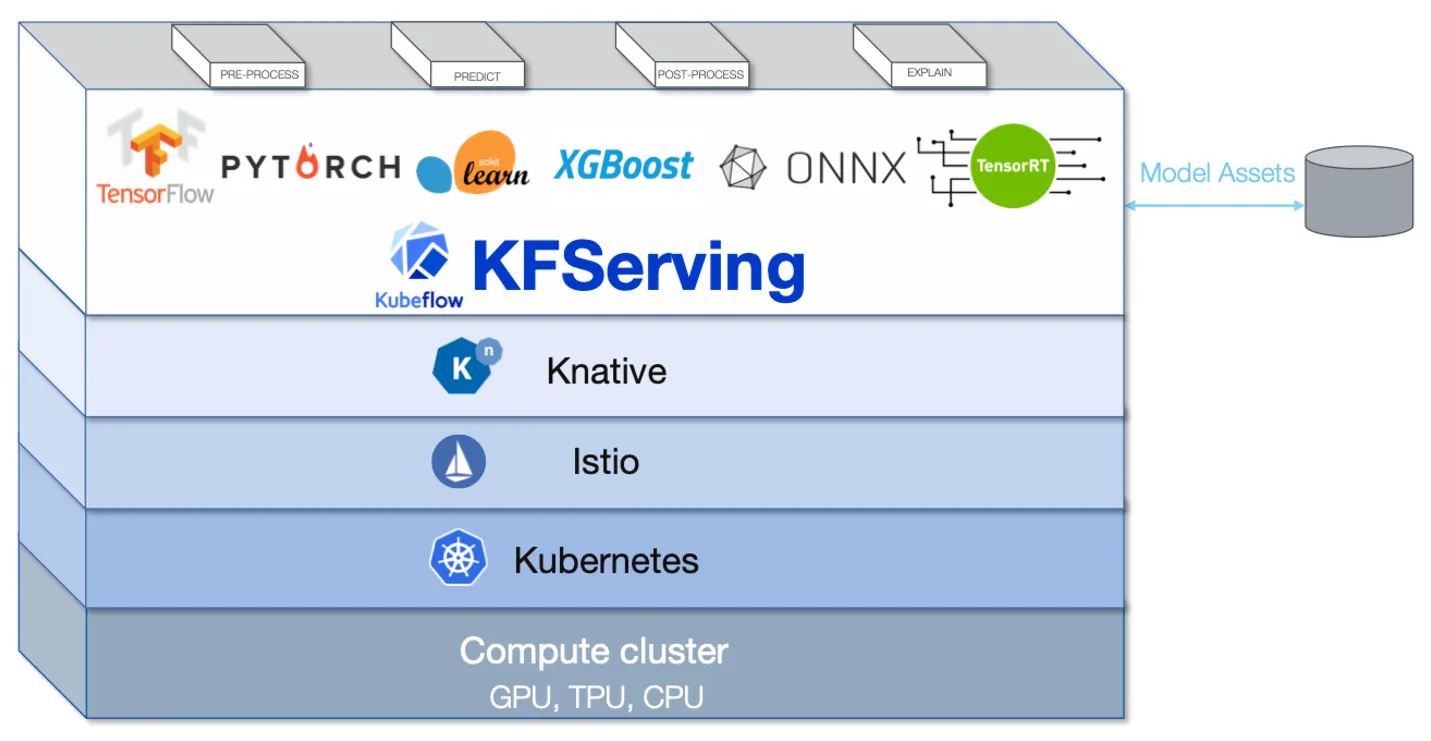
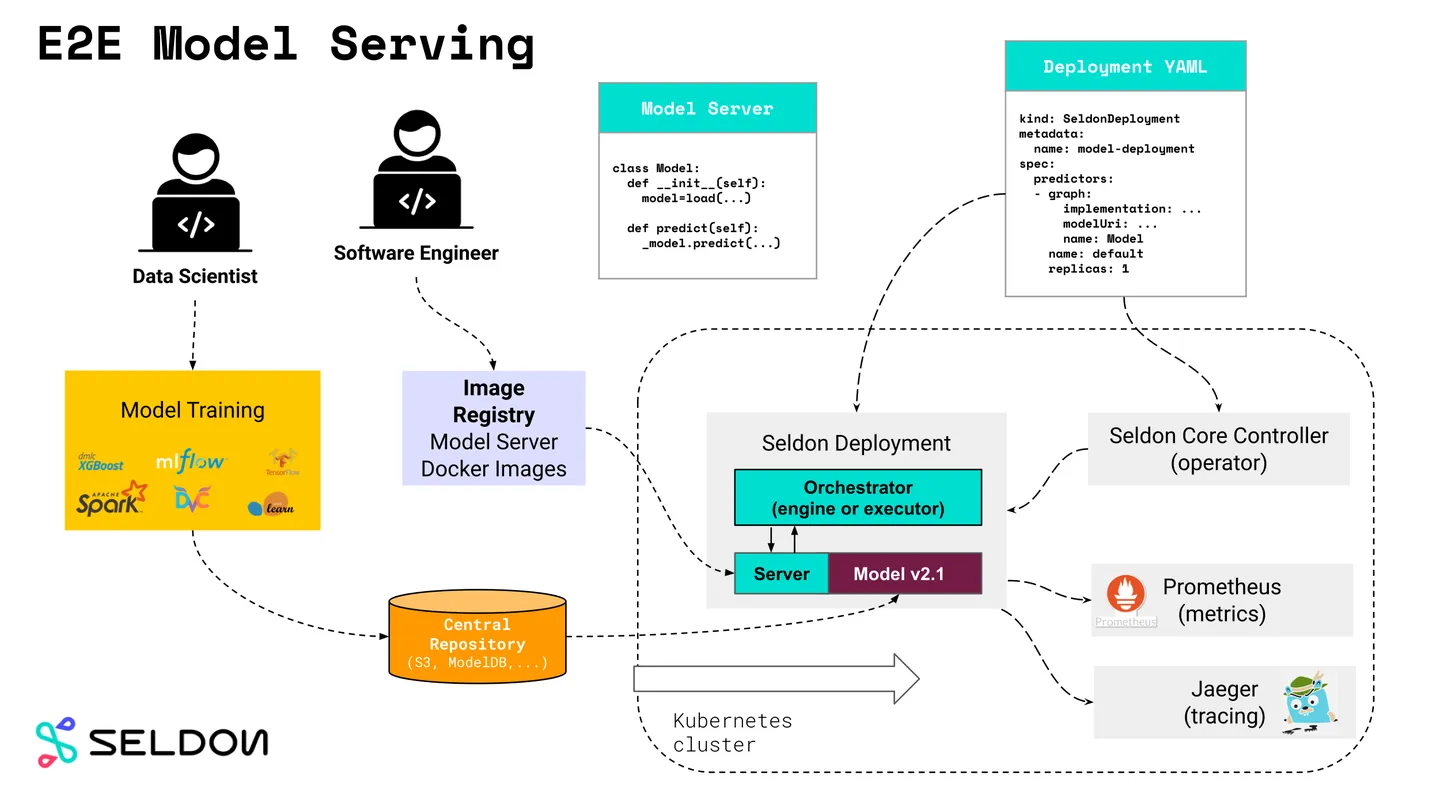


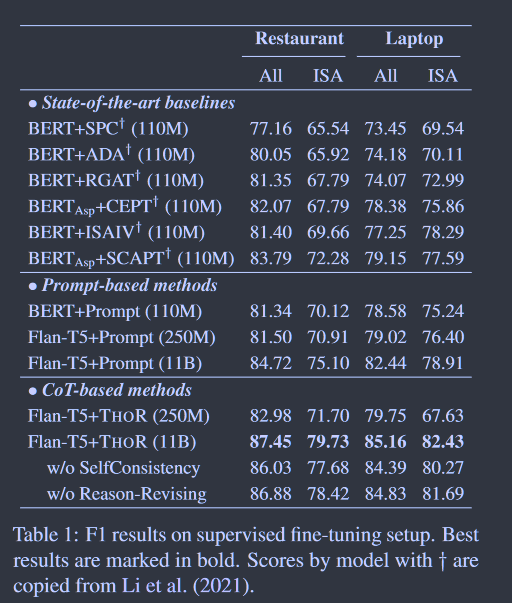 表1:有监督微调设置下的F1结果。最好的结果用粗体标出。表1中带"的模型得分复制自Li et al. ( 2021 )。
表1:有监督微调设置下的F1结果。最好的结果用粗体标出。表1中带"的模型得分复制自Li et al. ( 2021 )。 表2:零样本学习设定的模型结果。我们重新实现了零样本性能的最先进的基线。" ZeroCoT '表示用零样本学习CoT提示LLM,'让我们一步一步思考' (Brown 等, 2020)。
表2:零样本学习设定的模型结果。我们重新实现了零样本性能的最先进的基线。" ZeroCoT '表示用零样本学习CoT提示LLM,'让我们一步一步思考' (Brown 等, 2020)。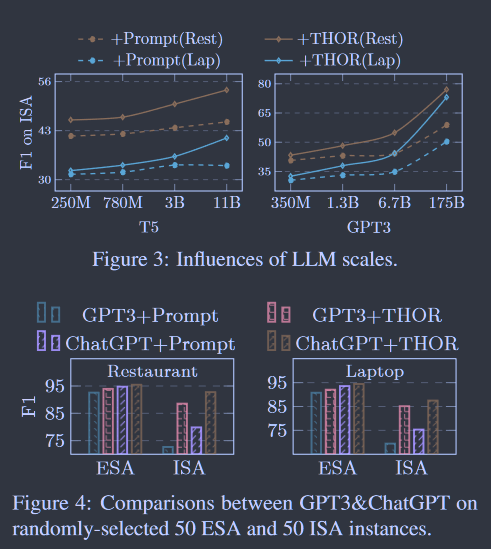
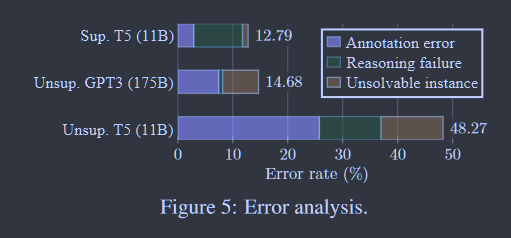 图5:误差分析。
图5:误差分析。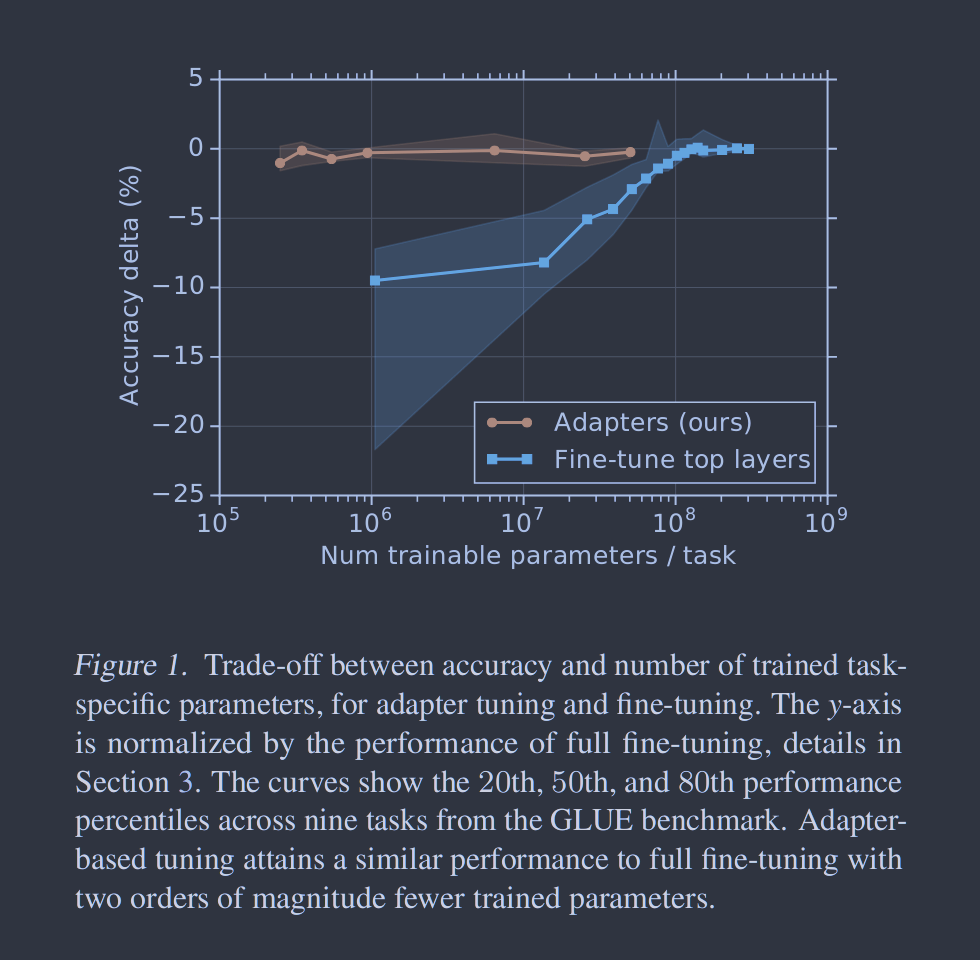
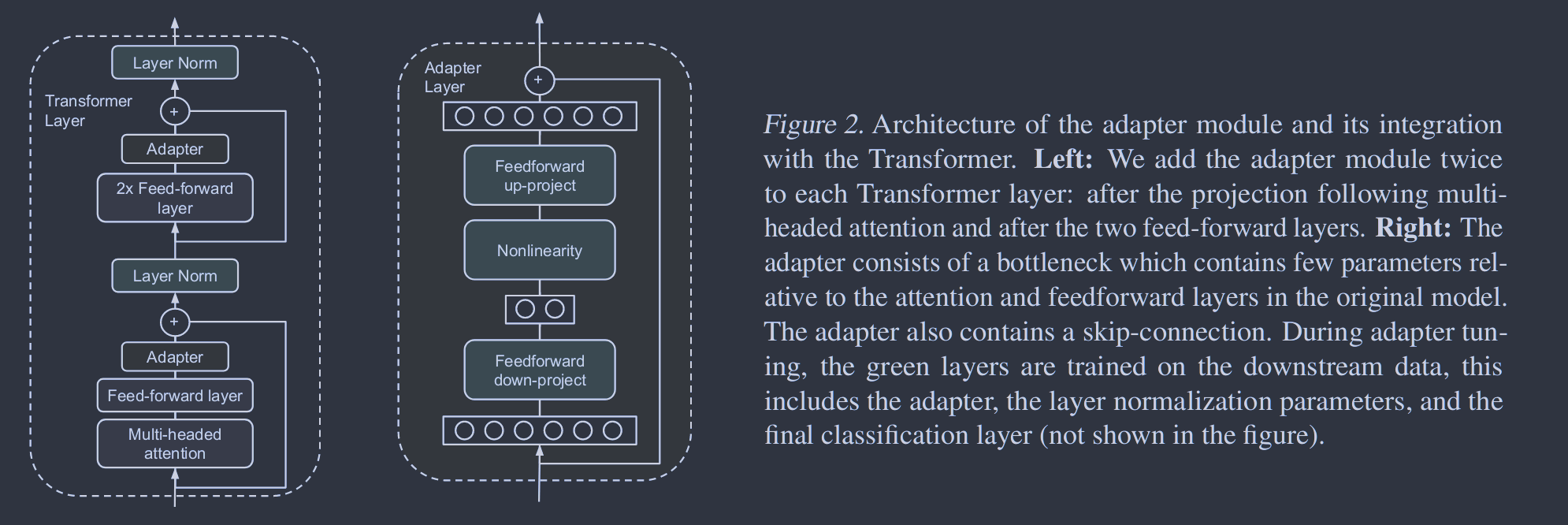
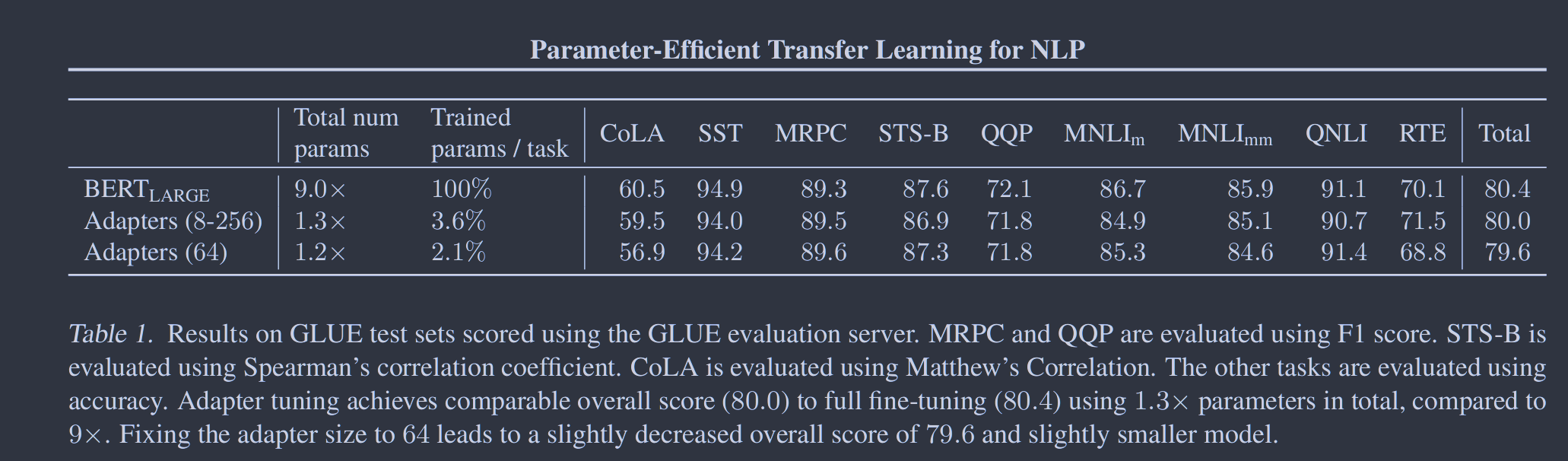
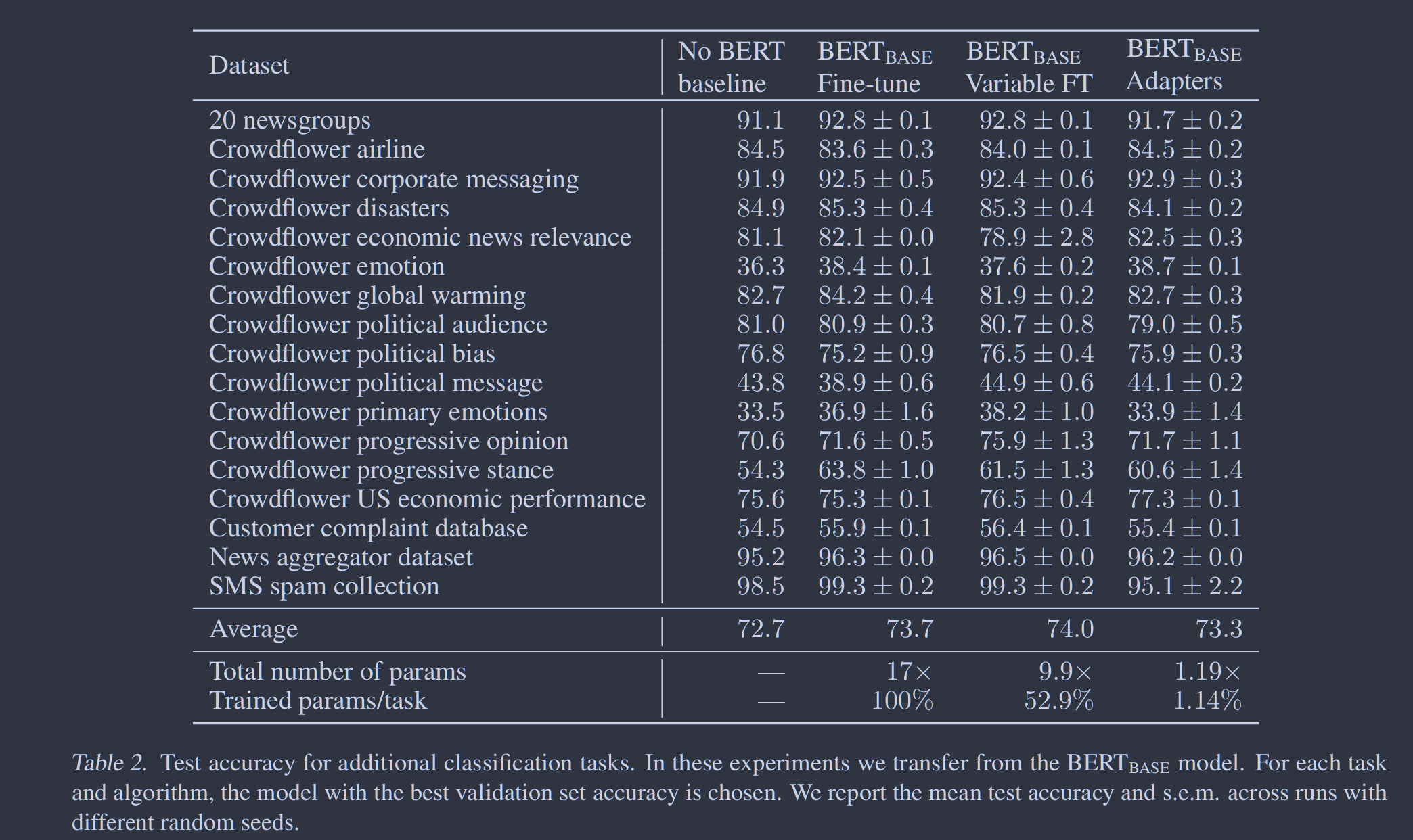
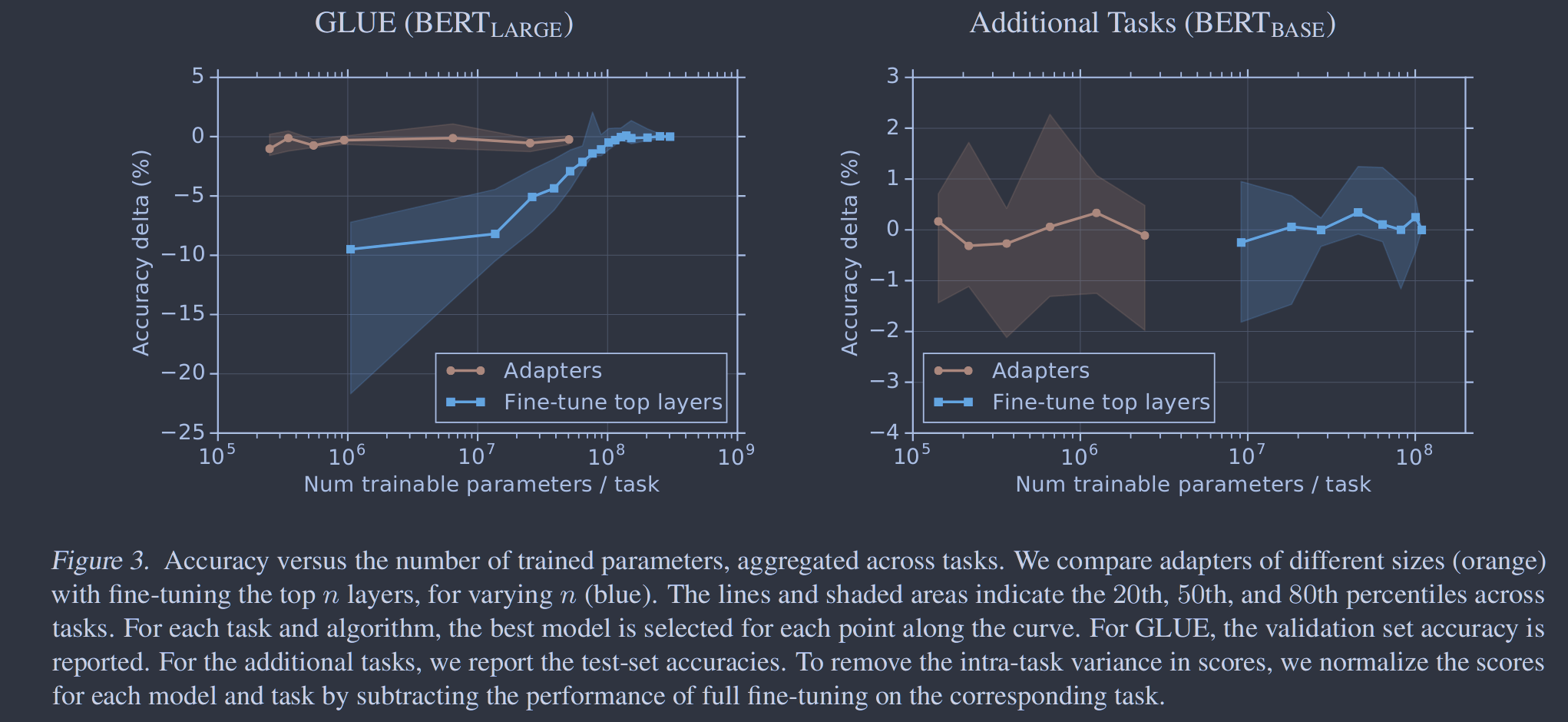 图3. 准确性与训练参数的数量,跨任务聚合。我们比较了不同大小的适配器(橙色)和微调前n层,对于不同的n (蓝色)。线条和阴影区域表示跨任务的第20、50和80百分位数。针对每一个任务和算法,为曲线上的每一个点选择最佳模型。对于GLUE,报告了验证集准确率。对于额外的任务,我们报告了测试集的准确率。为了消除评分中的任务内差异,我们通过减去在相应任务上的完全微调的性能来归一化每个模型和任务的评分。
图3. 准确性与训练参数的数量,跨任务聚合。我们比较了不同大小的适配器(橙色)和微调前n层,对于不同的n (蓝色)。线条和阴影区域表示跨任务的第20、50和80百分位数。针对每一个任务和算法,为曲线上的每一个点选择最佳模型。对于GLUE,报告了验证集准确率。对于额外的任务,我们报告了测试集的准确率。为了消除评分中的任务内差异,我们通过减去在相应任务上的完全微调的性能来归一化每个模型和任务的评分。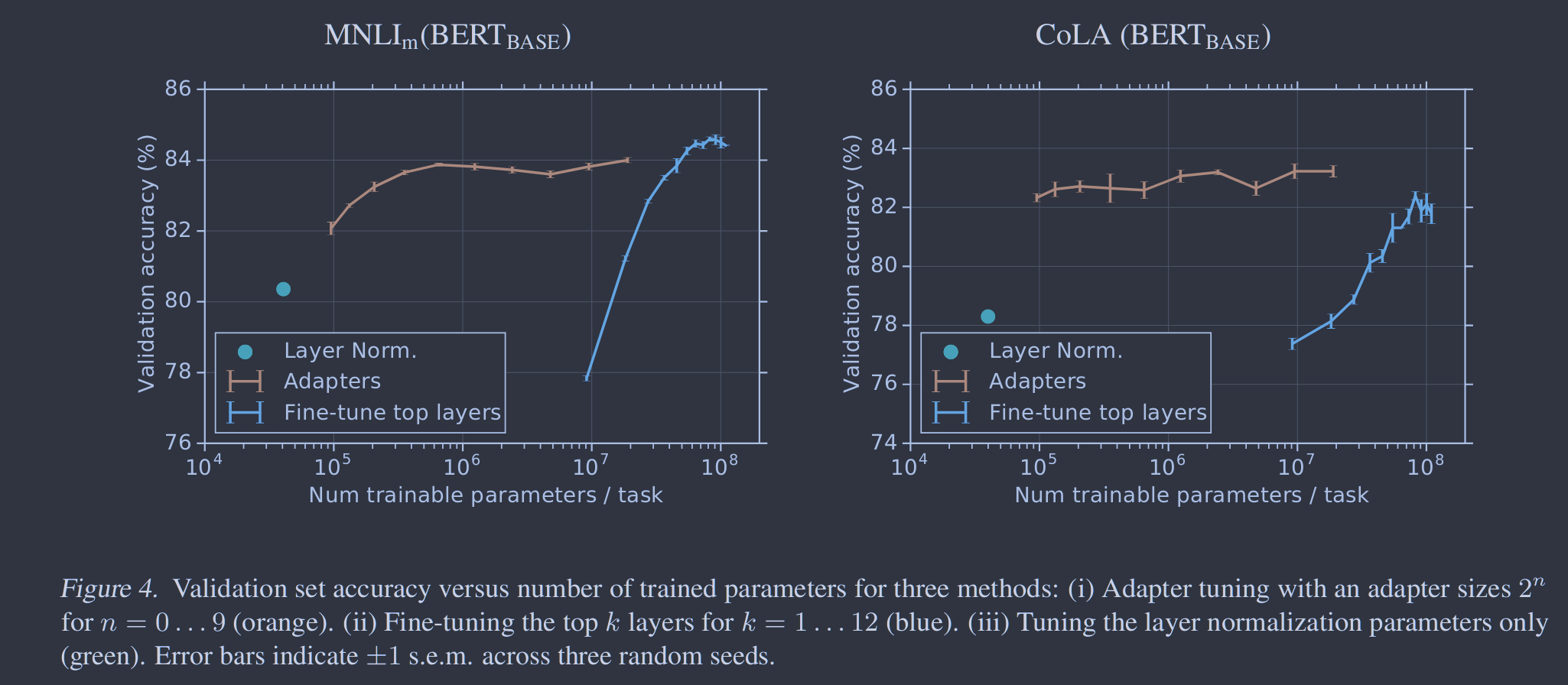
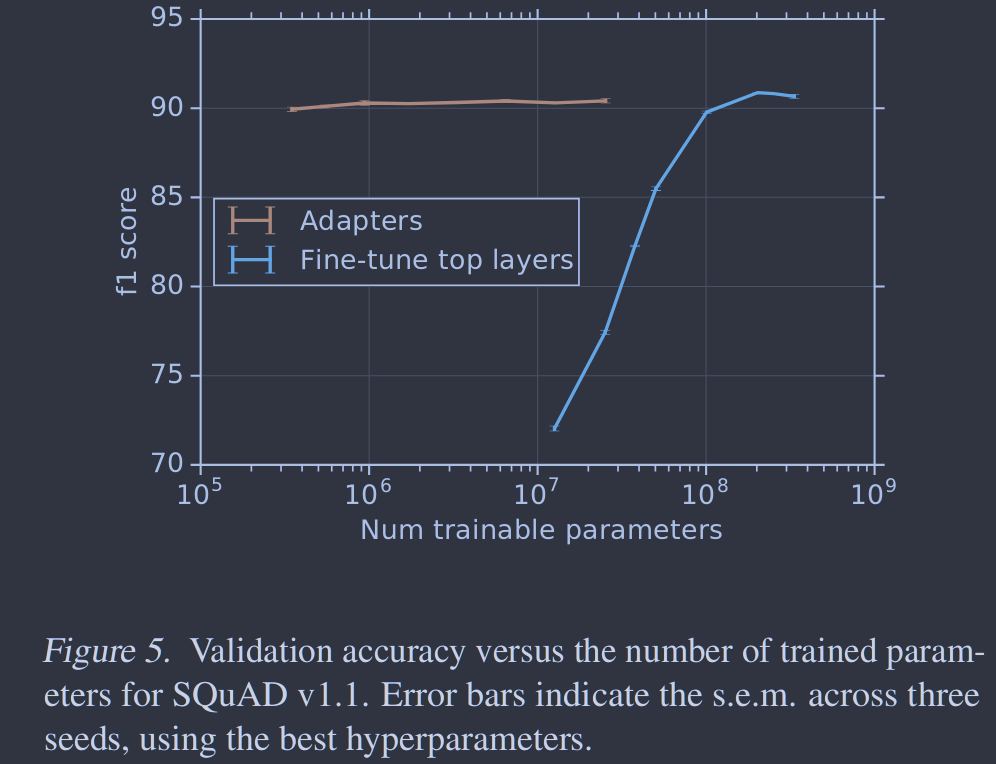 图5. 验证SQuAD v1.1的准确性与训练参数的数量。使用最佳超参数,误差条表示跨越三个种子的s.e.m.
图5. 验证SQuAD v1.1的准确性与训练参数的数量。使用最佳超参数,误差条表示跨越三个种子的s.e.m.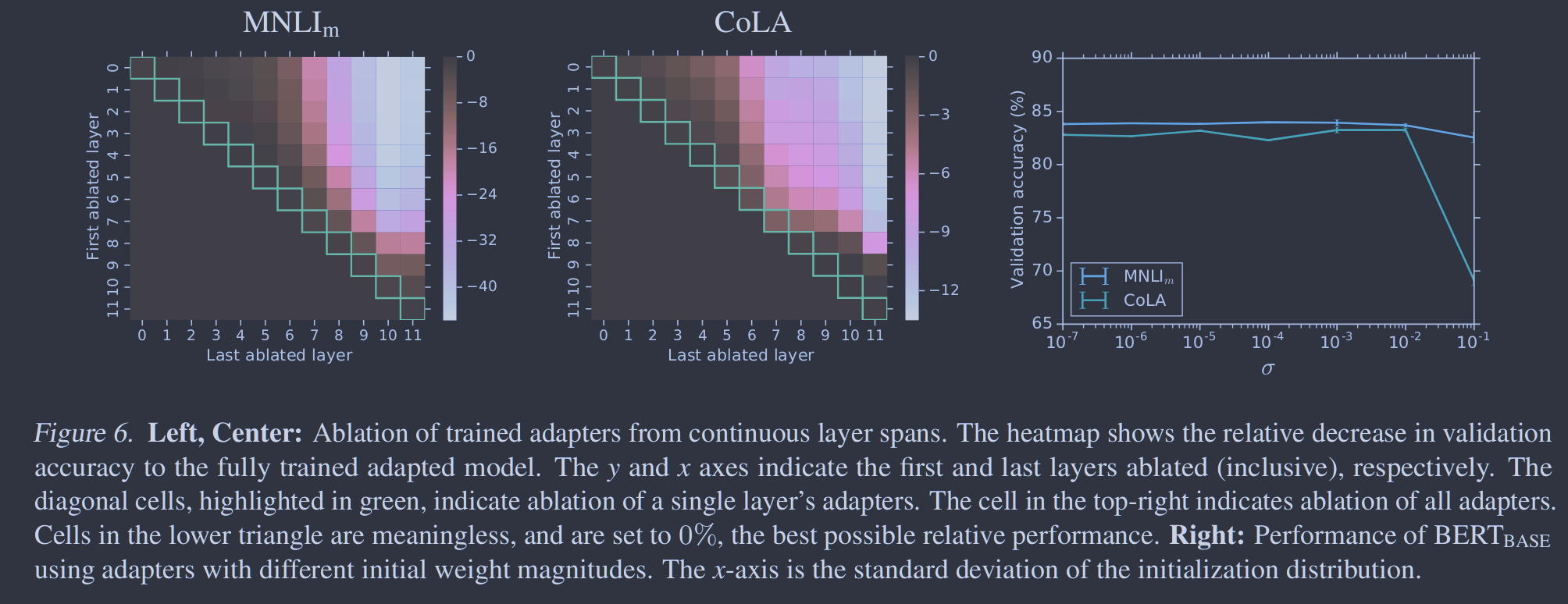 图6. 左,中心:从连续层跨中烧蚀训练好的适配器。热图显示了验证精度相对于充分训练的适应模型的相对下降。y和x轴分别表示第一层和最后一层消融(包括在内)。在绿色中突出的对角线细胞表明单层适配器的消融。右上角的单元格表示所有适配器的消融。下三角形中的细胞是没有意义的,并且设置为0 %,相对性能最好。正确:使用不同初始权重大小的适配器的BERTBASE的性能。x轴是初始化分布的标准差。
图6. 左,中心:从连续层跨中烧蚀训练好的适配器。热图显示了验证精度相对于充分训练的适应模型的相对下降。y和x轴分别表示第一层和最后一层消融(包括在内)。在绿色中突出的对角线细胞表明单层适配器的消融。右上角的单元格表示所有适配器的消融。下三角形中的细胞是没有意义的,并且设置为0 %,相对性能最好。正确:使用不同初始权重大小的适配器的BERTBASE的性能。x轴是初始化分布的标准差。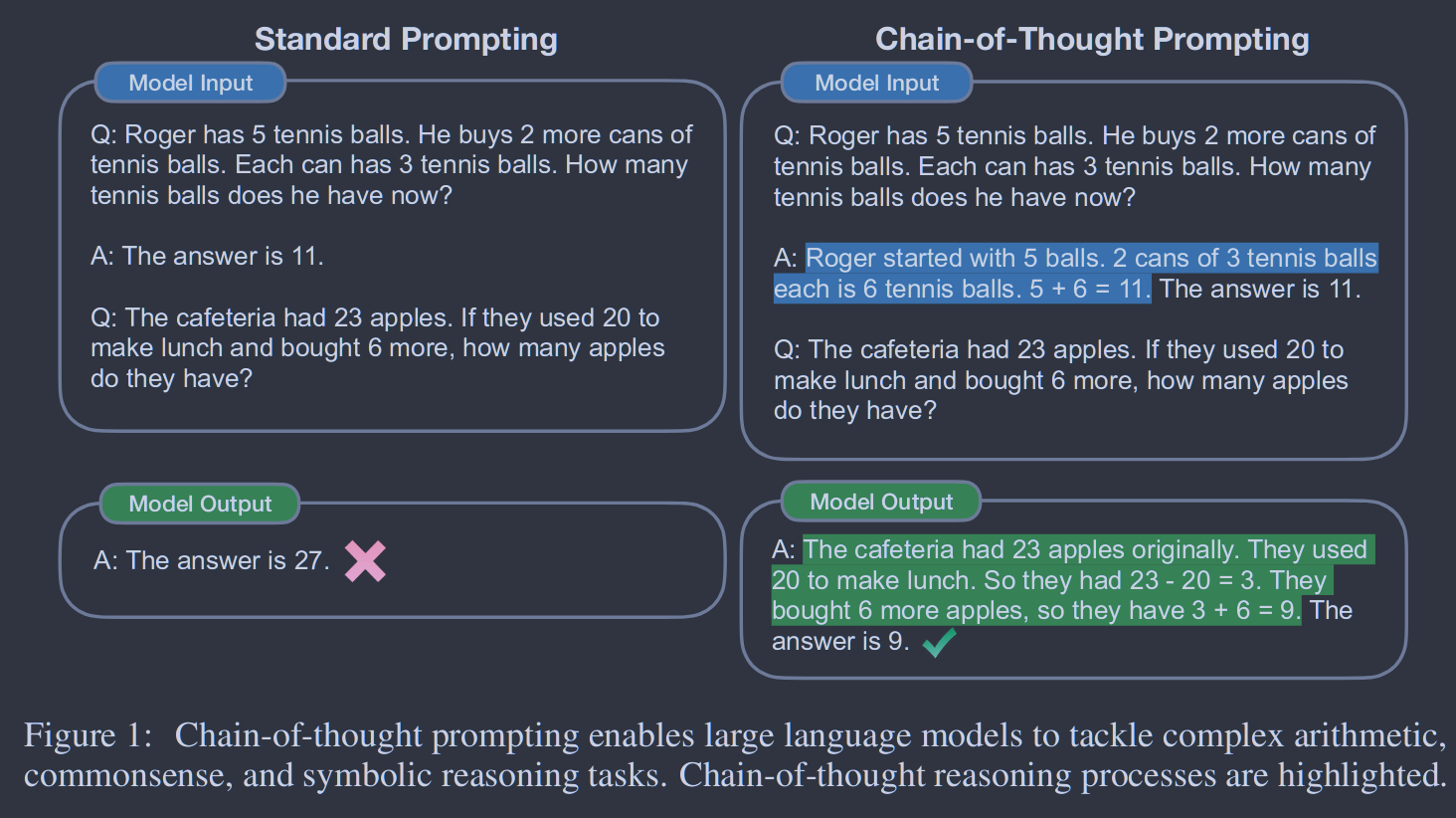 图1:思想链提示使大型语言模型能够处理复杂的算术、常识和符号推理任务。突出了思维链推理过程。
图1:思想链提示使大型语言模型能够处理复杂的算术、常识和符号推理任务。突出了思维链推理过程。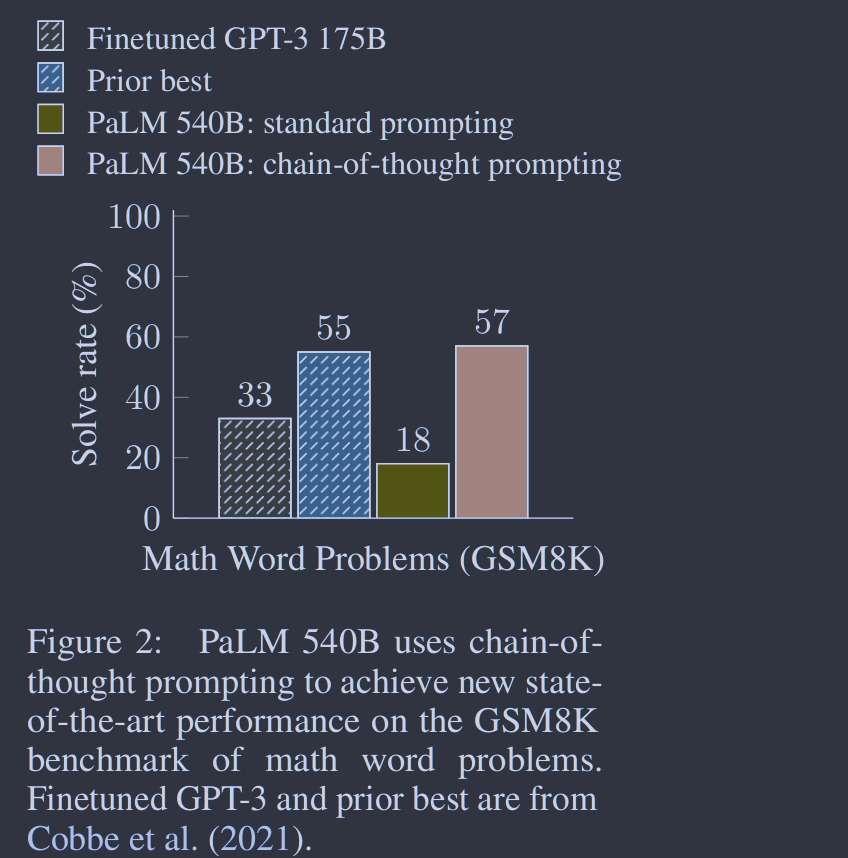
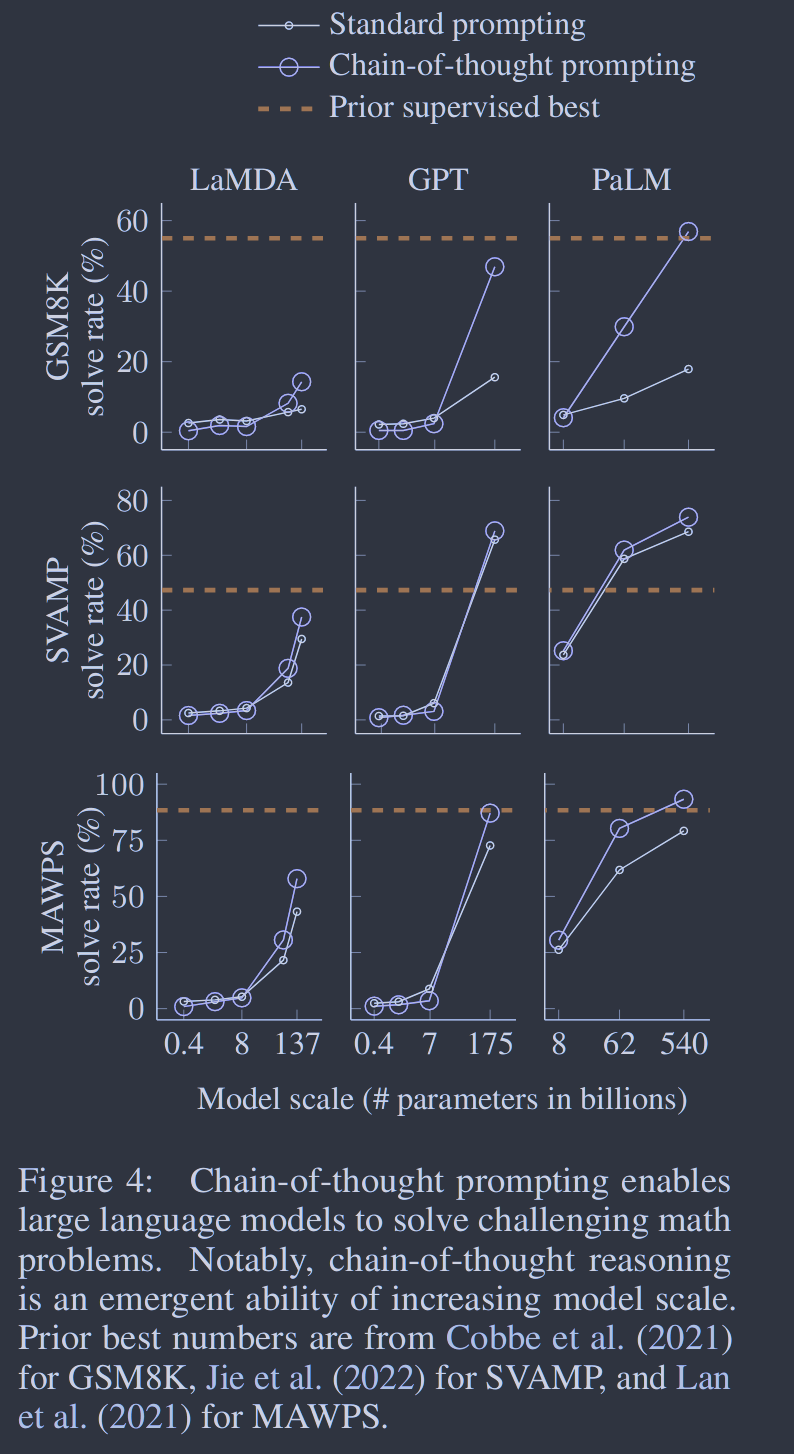
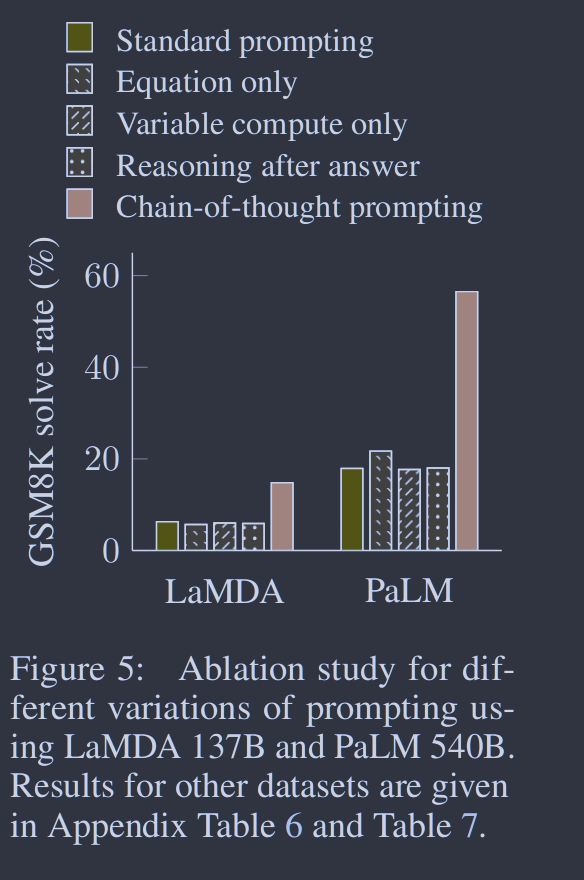 图5. 为La MDA 137B和Pa LM 540B对不同提示变化的消融研究。其他数据集的结果见附录表6和表7。
图5. 为La MDA 137B和Pa LM 540B对不同提示变化的消融研究。其他数据集的结果见附录表6和表7。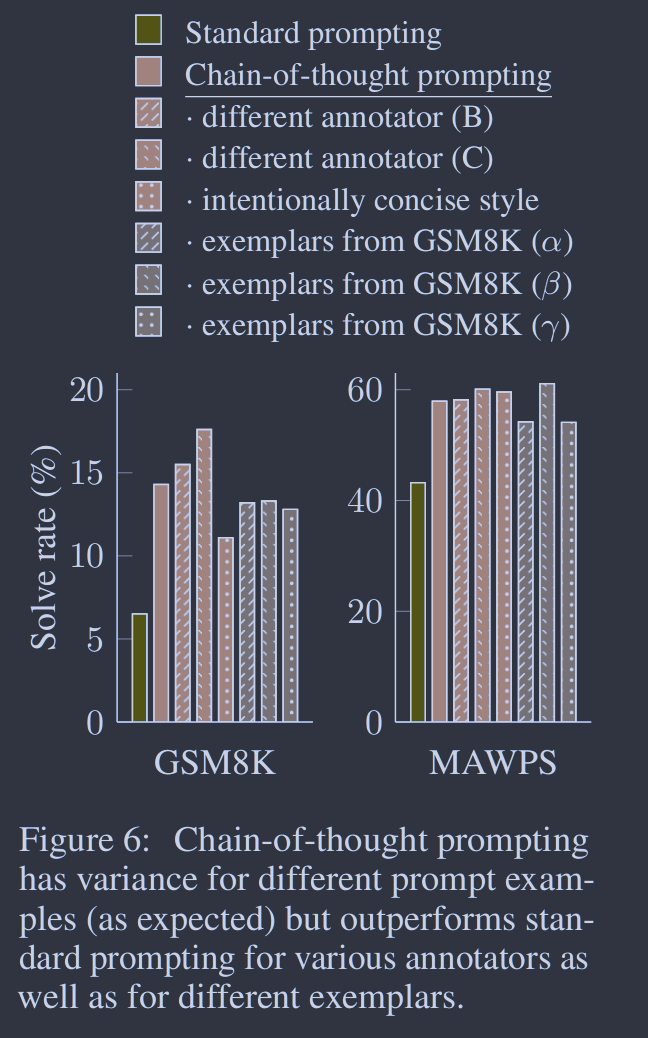 图6:思维链提示对不同提示样例有差异(如预期),但对不同注释者和不同示例都优于标准提示。
图6:思维链提示对不同提示样例有差异(如预期),但对不同注释者和不同示例都优于标准提示。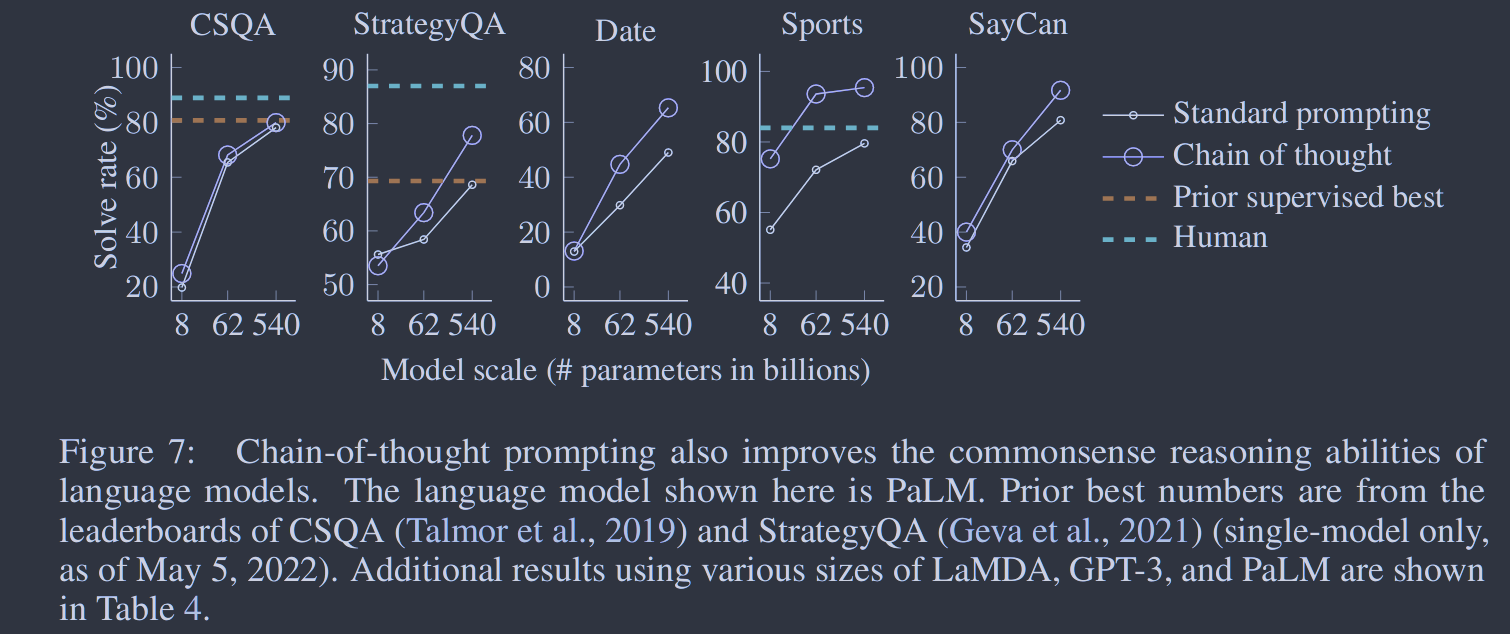 图7:思维链提示也提高了语言模型的常识推理能力。这里展示的语言模型是PaLM。先前最好的数字来自CSQA ( Talmor等, 2019)和StrategyQA ( Geva等, 2021) (仅限单模型,截至2022年5月5日)的排行榜。使用不同大小的La MDA、GPT - 3和Pa LM的附加结果如表4所示。
图7:思维链提示也提高了语言模型的常识推理能力。这里展示的语言模型是PaLM。先前最好的数字来自CSQA ( Talmor等, 2019)和StrategyQA ( Geva等, 2021) (仅限单模型,截至2022年5月5日)的排行榜。使用不同大小的La MDA、GPT - 3和Pa LM的附加结果如表4所示。
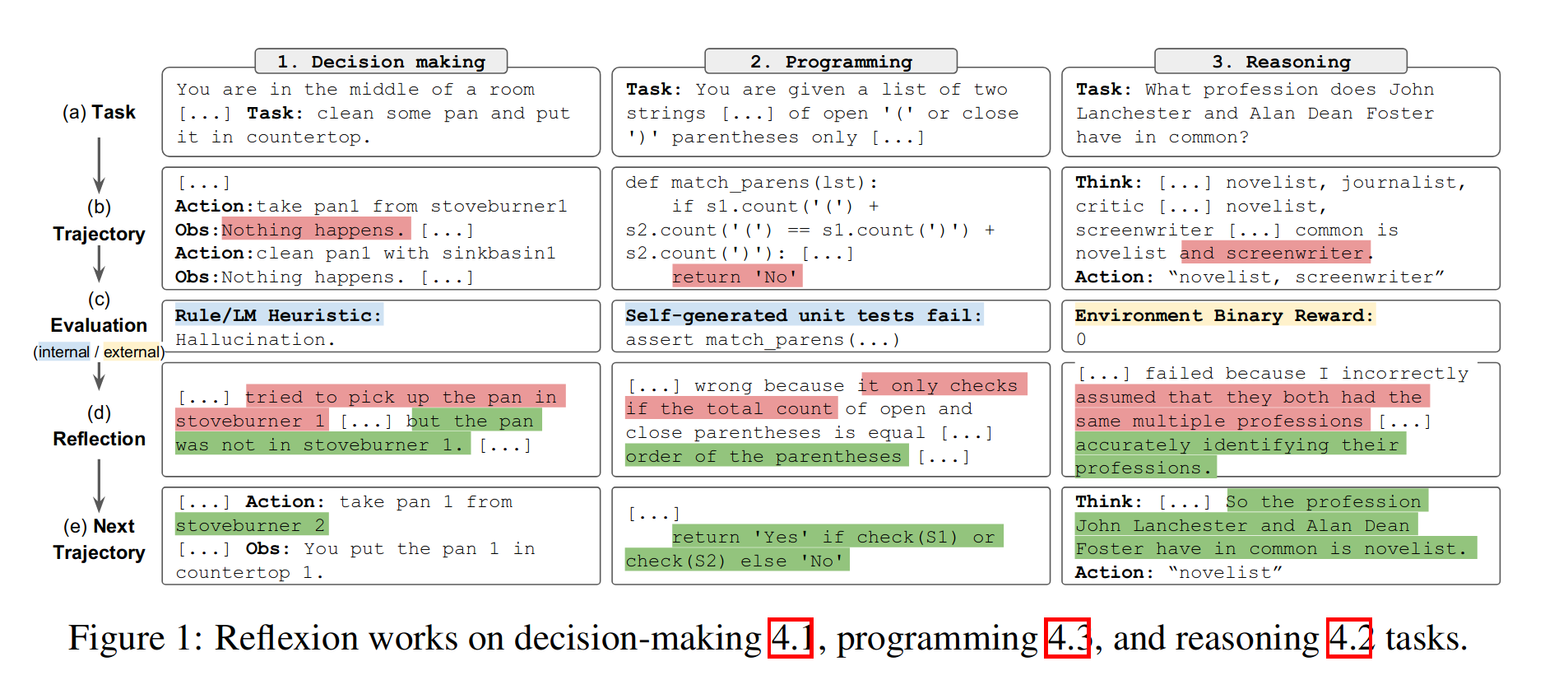
 图3:( a ) AlfWorld在134个任务中的表现,显示了使用启发式( Heuristic )和二分类( GPT )的自我评估技术解决任务的累积比例。( b )按故障原因对AlfWorld轨迹进行分类。
图3:( a ) AlfWorld在134个任务中的表现,显示了使用启发式( Heuristic )和二分类( GPT )的自我评估技术解决任务的累积比例。( b )按故障原因对AlfWorld轨迹进行分类。

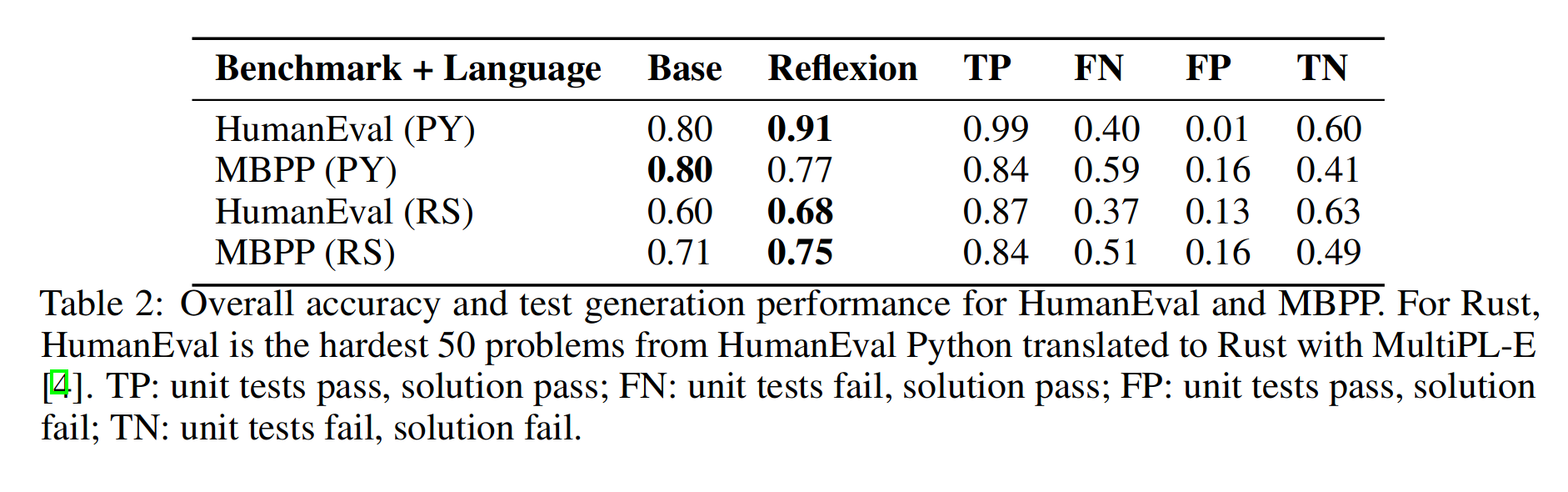 表2:HumanEval和MBPP的总体精度和测试生成性能。对于Rust问题,从HumanEval Python翻译成Rust问题的MultiPL-E[ 4 ]中,HumanEval是最难的50个问题。TP:单元测试合格,解决方案合格;FN:单元测试失败,解决方案通过;FP:单元测试通过,解决方案失败;TN:单元测试失败,解决方案失败。
表2:HumanEval和MBPP的总体精度和测试生成性能。对于Rust问题,从HumanEval Python翻译成Rust问题的MultiPL-E[ 4 ]中,HumanEval是最难的50个问题。TP:单元测试合格,解决方案合格;FN:单元测试失败,解决方案通过;FP:单元测试通过,解决方案失败;TN:单元测试失败,解决方案失败。 表3:以GPT-4为基准模型的Reflexion方法在Human Eval Rust - 50最难问题上各种折衷方法的Pass@1精度
表3:以GPT-4为基准模型的Reflexion方法在Human Eval Rust - 50最难问题上各种折衷方法的Pass@1精度